Voxtral Mini 3B
mistralai/Voxtral-Mini-3B-2507
published Jul 2025 · updated Jul 2025
Voxtral Mini 3B is a multimodal audio chat model that excels at speech transcription, translation, and audio understanding while retaining strong text capabilities.
specs
| Task | Speech Understanding & Transcription |
| Architecture | Whisper large-v3 encoder + Ministral 3B decoder |
| Parameters | 3B |
| License | Apache 2.0 |
| Context Length | 32k tokens |
| GPU Memory (bf16) | ~9.5 GB |
about this model
Voxtral-Mini-3B-2507 is a multimodal audio chat model that combines speech transcription, translation, and understanding with text capabilities, built on the Ministral-3B language model backbone.
Key Features
- Dedicated transcription mode: Automatically detects source language and transcribes speech with high accuracy; uses
temperature=0.0for optimal results. - Long-form context: Supports up to 32k tokens, handling audio of up to 30 minutes for transcription or 40 minutes for understanding tasks.
- Built-in Q&A and summarization: Processes spoken questions and generates structured summaries without requiring a separate ASR pipeline.
- Multilingual: State-of-the-art performance in English, Spanish, French, Portuguese, Hindi, German, Dutch, and Italian, with automatic language detection.
- Function calling from voice: Enables direct triggering of backend functions, workflows, or API calls based on spoken intents.
- Text capability preserved: Retains the full text understanding performance of Ministral-3B.
Benchmark Results
Audio: Average word error rate (WER) across the FLEURS, Mozilla Common Voice, and Multilingual LibriSpeech benchmarks:
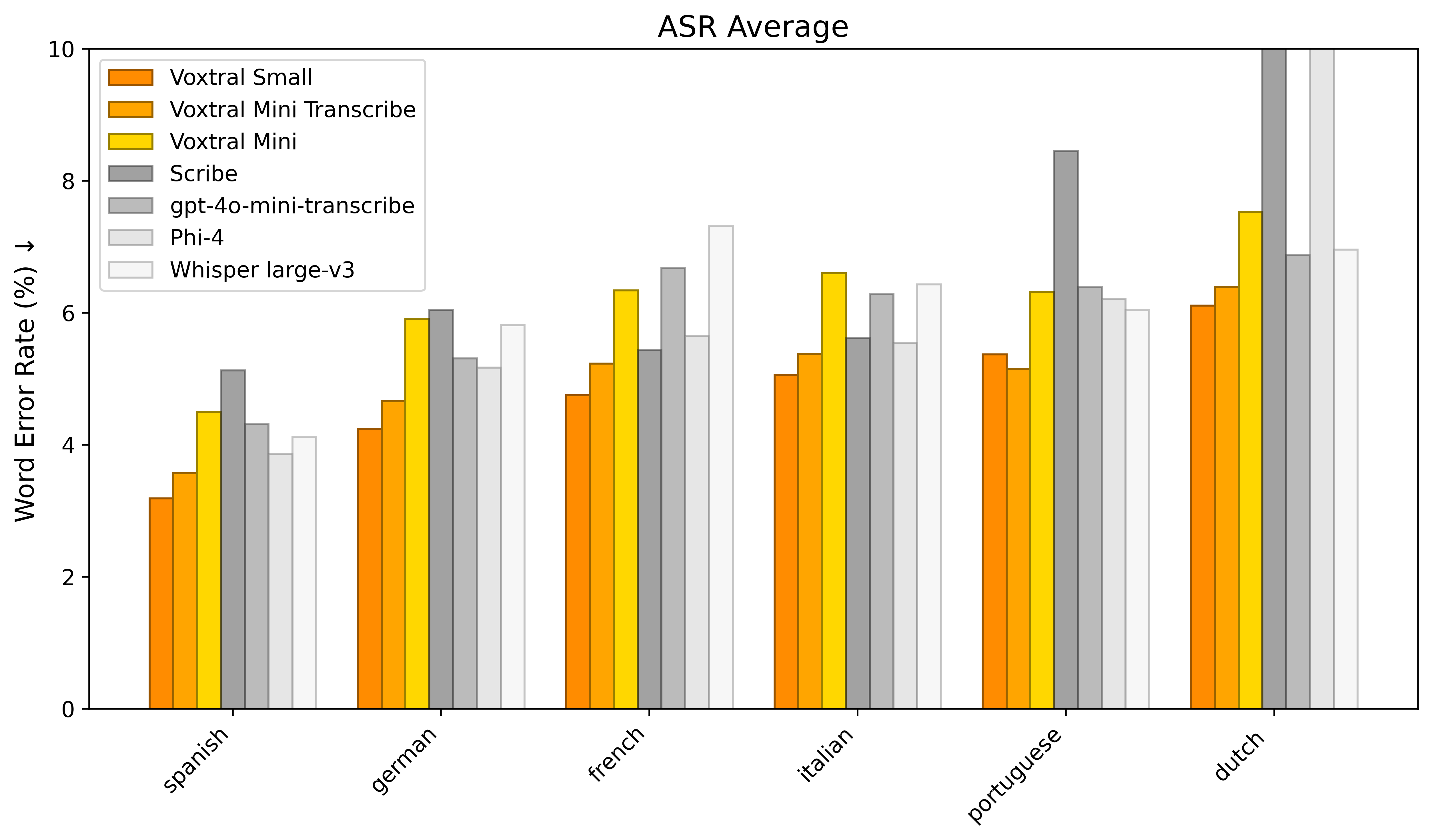
Text: Retained text benchmark performance (e.g., MMLU, HellaSwag) compared to Ministral-3B:
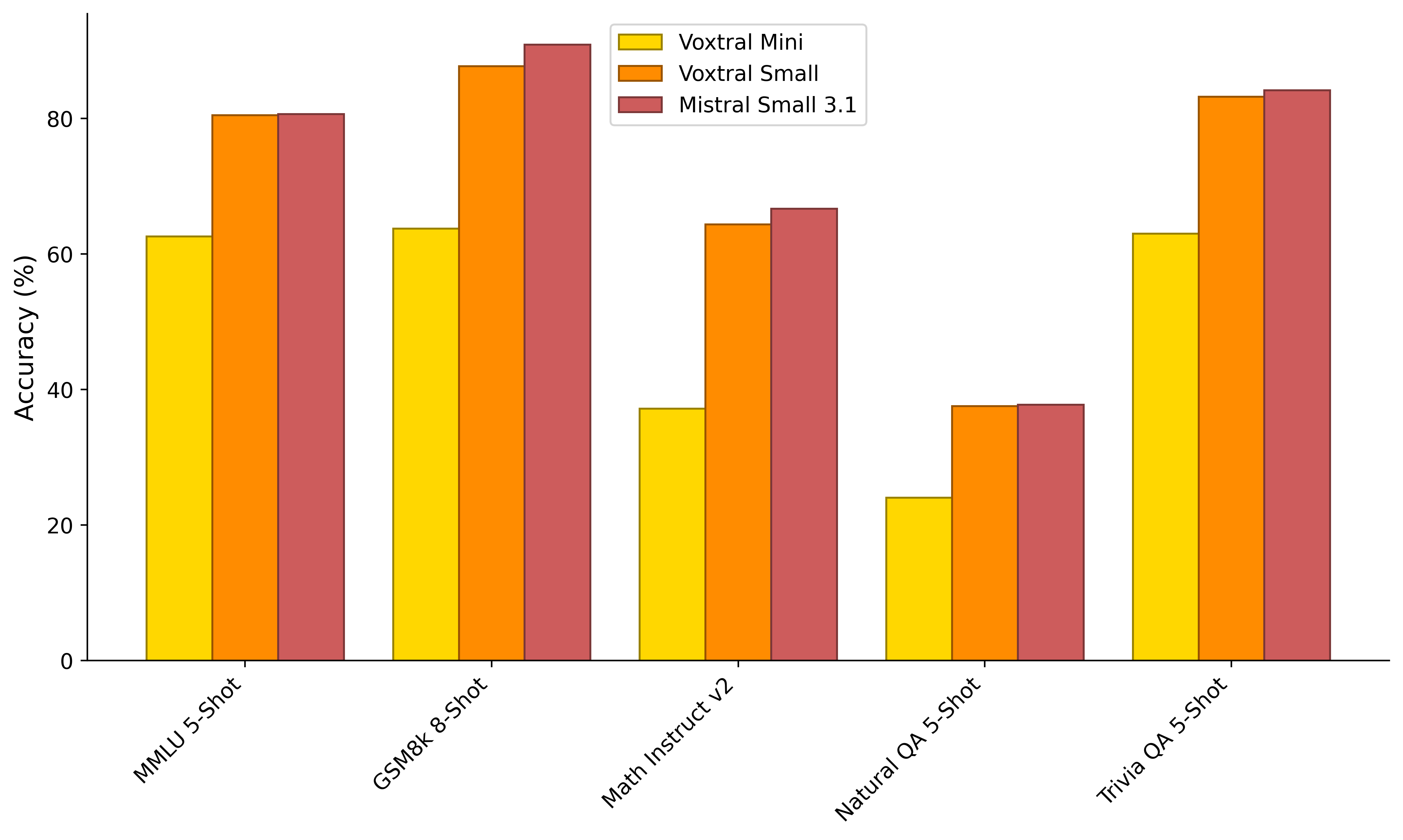
Architecture and Performance
- Audio encoder based on Whisper large-v3 with 50 Hz frame rate; adapter layer downsamples audio embeddings by 4×; processes 30-second audio chunks independently (log-Mel spectrograms with 128 bins, 160 hop-length).
- Three new speech evaluation benchmarks introduced: MMLU Speech, TriviaQA Speech, and GSM8K Speech.
- Comparison models: Voxtral Mini is benchmarked against GPT-4o mini and Gemini 2.5 Flash for speech QA and summarization.
- GPU memory requirement: approximately 9.5 GB in bf16 or fp16 precision.
- Released under Apache 2.0 license (see research paper for full details).
best for
- ·Transcribing long audio files (up to 30 minutes) with automatic language detection
- ·Multilingual audio understanding, summarization, and Q&A without separate ASR
- ·Voice-enabled function calling and workflow automation from spoken intents
- ·Comparing and analyzing multiple audio clips in a single conversation
FAQ
It is designed for speech transcription, translation, audio understanding, summarization, and voice-driven function calling, all while retaining strong text capabilities.
Input: audio files (e.g., MP3) and text. Output: transcribed text or chat responses. It supports multiple audios per message and multi-turn conversations.
Running Voxtral Mini 3B requires approximately 9.5 GB of GPU RAM in bf16 or fp16 precision.
It is released under the Apache 2.0 license.
Use the OpenAI-compatible endpoint provided by gigarouter with your API key. Set the model name to mistralai/Voxtral-Mini-3B-2507 and send requests for chat completions or audio transcriptions.
We're benchmarking and onboarding Voxtral Mini 3B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.