ColBERT v2
colbert-ir/colbertv2.0
published Jun 2023 · updated Apr 2024
ColBERT v2 is a retrieval model that uses contextualized late interaction for fast and accurate passage search over large text collections.
specs
| Task | Passage Retrieval |
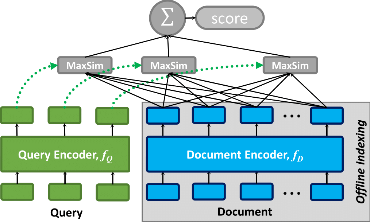
| Architecture | BERT with late interaction (MaxSim) |
| Training Data | MS MARCO Passage Ranking |
| Speed | Tens of milliseconds per query (with PLAID engine) |
about this model
Key Strengths
- Fine-grained contextual late interaction for high retrieval accuracy.
- Pre-computed document representations enable offline indexing and fast query processing.
- ColBERTv2 reduces the space footprint of late interaction models by 6–10x compared to vanilla late interaction.
- PLAID engine speeds up vanilla ColBERTv2 search latency by up to 7x on GPU and 45x on CPU while maintaining state-of-the-art retrieval quality.
- Achieves latency of tens of milliseconds on GPU and tens to few hundred milliseconds on CPU at large scale (up to 140M passages).
Benchmark Results
ColBERTv2 has been evaluated on the LoTTE benchmark test set, yielding the following Success@5 scores:
| Topic | Search Queries | Forum Queries |
|---|---|---|
| Writing | 80.1 | 76.3 |
| Recreation | 72.3 | 70.8 |
| Science | 56.7 | 46.1 |
| Technology | 66.1 | 53.6 |
| Lifestyle | 84.7 | 76.9 |
| Pooled | 71.6 | 63.4 |
ColBERTv2 is competitive with existing BERT-based models and outperforms every non-BERT baseline, while executing two orders-of-magnitude faster and requiring four orders-of-magnitude fewer FLOPs per query. It has also been adapted for Open-Domain Question Answering (ColBERT-QA), attaining state-of-the-art extractive OpenQA performance on Natural Questions, SQuAD, and TriviaQA.

best for
- ·End-to-end passage search over large document collections
- ·Open-domain question answering
- ·Multi-hop reasoning retrieval
FAQ
It is best for fast, accurate passage retrieval in search and open-domain QA tasks, especially over large corpora.
With the PLAID engine, it achieves tens of milliseconds on GPU and tens to few hundred milliseconds on CPU at scale.
It uses 2-bit residual compression, reducing storage by 6-10x compared to vanilla late interaction.
Use the OpenAI-compatible endpoint with your API key, sending the query and optional parameters as per gigarouter documentation.
At inference, it accepts plain text queries; internally it uses token-level embeddings for late interaction scoring.
We're benchmarking and onboarding ColBERT v2 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.