Chandra OCR 2
datalab-to/chandra-ocr-2
published Mar 2026 · updated Jun 2026
Chandra OCR 2 is a vlm model that converts images and PDFs into structured markdown, HTML, and JSON while preserving layout information.
specs
| Task | Optical Character Recognition (OCR) and Document Understanding |
| Architecture | Vision-Language Model (VLM) |
| License | Code: Apache 2.0; Model weights: Modified OpenRAIL-M (free for research, personal use, and startups under $2M funding/revenue; cannot be used competitively with Datalab API) |
about this model
Chandra OCR 2 is a vision-language model (VLM) that converts images and PDFs into structured Markdown, HTML, or JSON while preserving document layout. It is hosted on Gigarouter as a managed, OpenAI-compatible API.
Key Capabilities
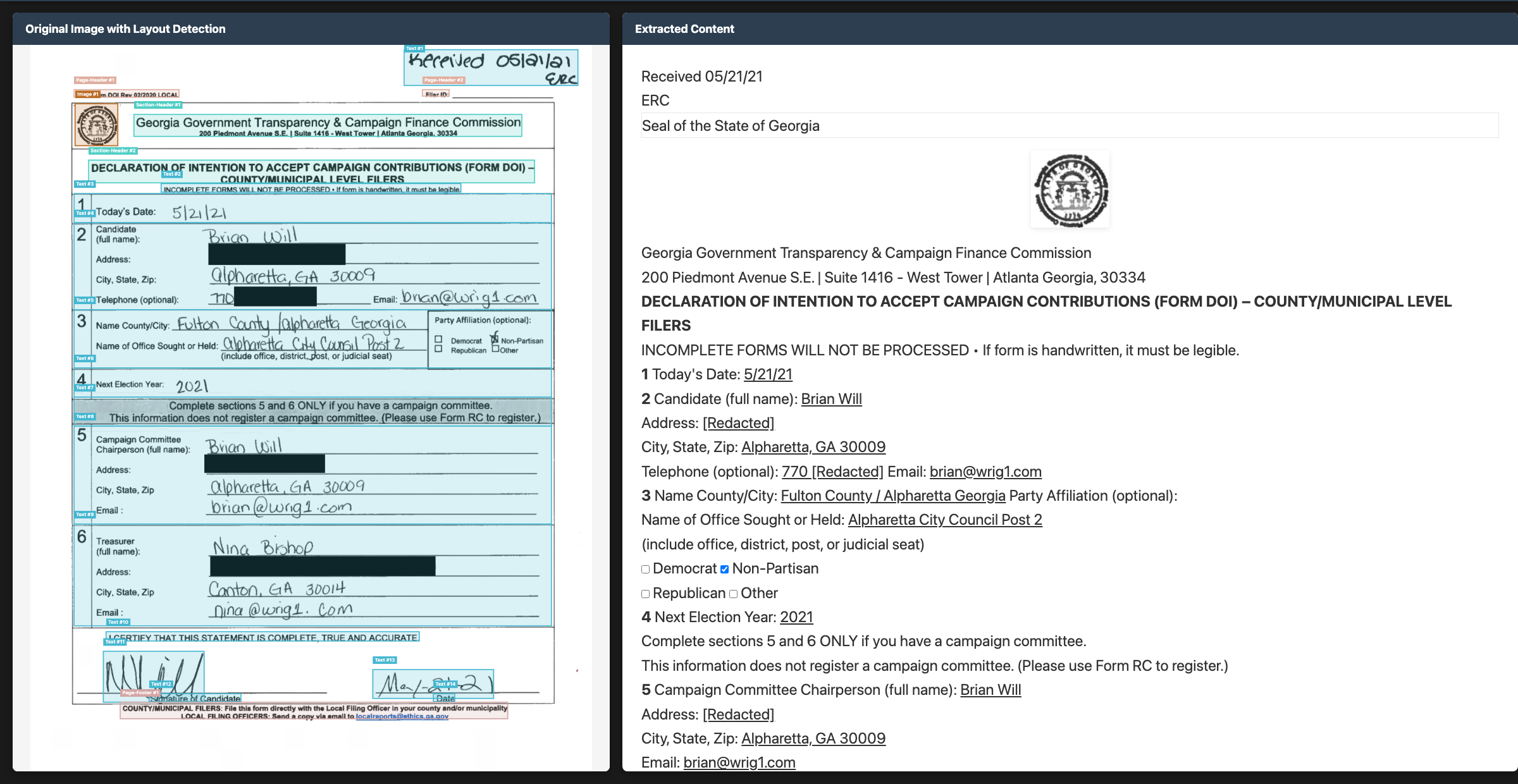
The model extracts text, tables, math, handwriting, checkboxes, and images with captions from documents. It supports 90+ languages and outputs structured formats with detailed layout information.
Benchmark Performance
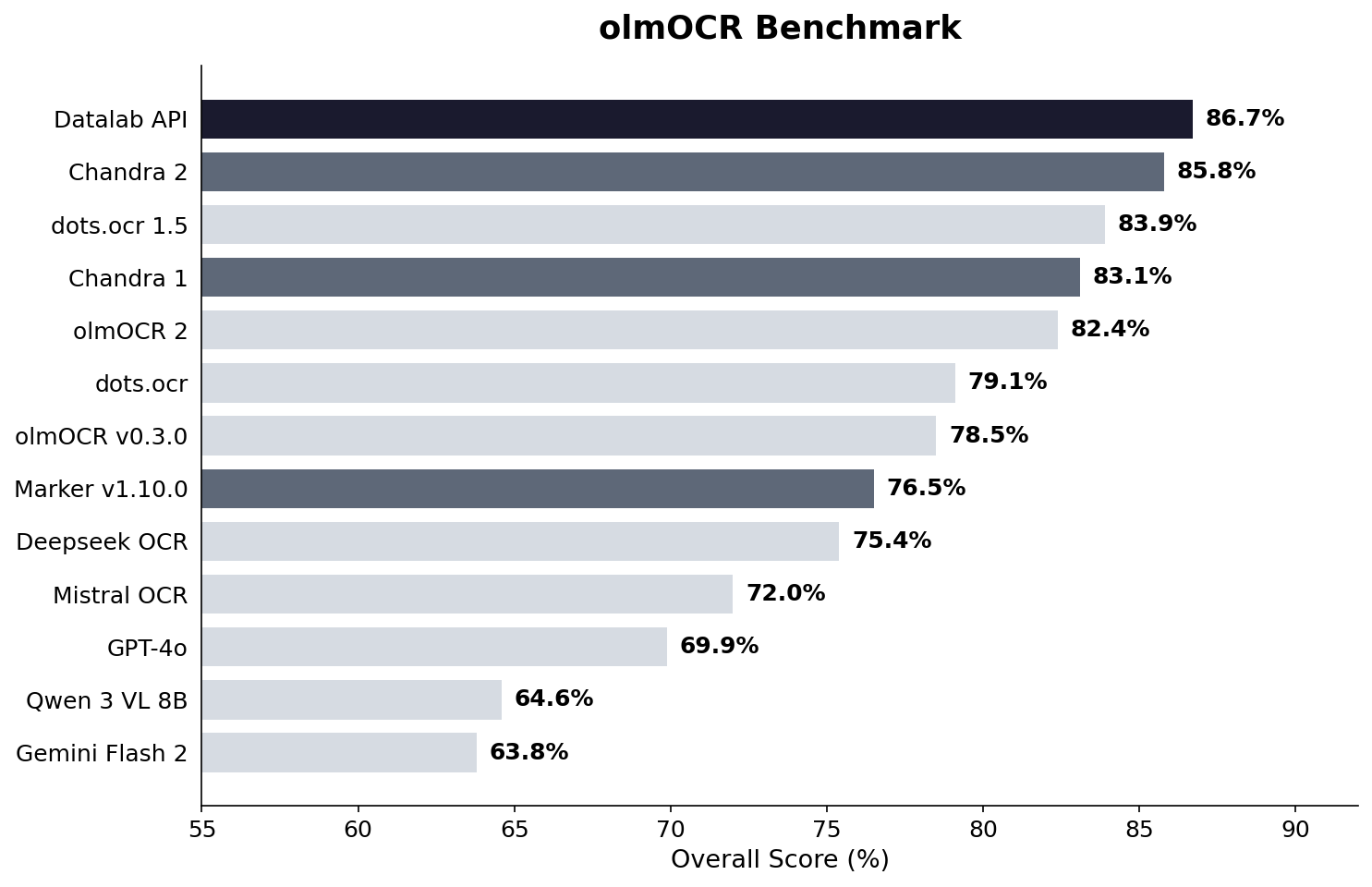
Chandra 2 achieves an 85.8% overall score on the olmOCR benchmark, with strong results across document types:
- ArXiv: 86.9%
- Old Scans Math: 89.1%
- Tables: 92.1%
- Multi column: 82.1%
- Long tiny text: 93.7%
On the 43-language multilingual benchmark, Chandra 2 averages 77.8%, a 12% improvement over Chandra 1 (69.4%). In the full 90-language evaluation, Chandra 2 averages 72.7% ± 1.2% compared to Gemini 2.5 Flash at 60.8% ± 1.3%. Languages with Chandra 2 scores above 90% include English (96.6%), German (94.8%), Italian (94.6%), French (93.7%), Swedish (93.3%), Danish (91.1%), Indonesian (91.6%), Polish (91.5%), Ukrainian (91.0%), Norwegian (90.5%), Breton (90.0%), Croatian (90.1%), and Serbian (90.3%).
Throughput
On a single NVIDIA H100 80GB GPU with vLLM and 96 concurrent sequences, Chandra 2 processes 1.44 pages per second with an average latency of 60 seconds and a P95 latency of 156 seconds. Real-world usage is estimated at 2 pages per second.
Output Formats
The model outputs Markdown, HTML, or JSON with detailed layout information, including image and diagram extraction with captions and structured data.


best for
- ·Converting scanned documents and PDFs to structured markdown or HTML
- ·Extracting text from complex layouts with tables, math, and multi-column formats
- ·Handwritten form and document transcription with layout preservation
- ·Multilingual OCR across 90+ languages
FAQ
It outputs markdown, HTML, and JSON with detailed layout information.
It supports 90+ languages, with a 77.8% average score on a 43-language multilingual benchmark.
The code is Apache 2.0. The model weights use a modified OpenRAIL-M license: free for research, personal use, and startups under $2M funding/revenue. It cannot be used competitively with the Datalab API.
Use the gigarouter OpenAI-compatible endpoint with your API key. Send an image or PDF as input and specify the desired output format (markdown, HTML, or JSON).
Benchmarked with vLLM on a single NVIDIA H100 80GB GPU, it achieves 1.44 pages/sec with 96 concurrent sequences, with an average latency of 60 seconds and a 0% failure rate.
We're benchmarking and onboarding Chandra OCR 2 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.