models / vision-language · coming soon
Qwen3-VL-4B-Instruct
Qwen/Qwen3-VL-4B-Instruct
A popular open vision-language model, with 3.7M downloads a month. gigarouter benchmarks and hosts it as an OpenAI-compatible API.
est. price
~$1.341
/ 1k images · estimated, set at launch
API providers
0
downloads / mo
3.7M
license
apache-2.0
about this model
Qwen3-VL-4B-Instruct is a dense vision-language model (VLM) built for multimodal understanding, visual grounding, and agentic tasks. It is hosted as a managed, OpenAI-compatible API on gigarouter, allowing developers to integrate vision-language capabilities without managing infrastructure.
Key Capabilities
- Visual Agent: Operates PC and mobile GUIs by recognizing elements, understanding functions, and invoking tools to complete tasks.
- Visual Coding: Generates Draw.io diagrams, HTML, CSS, and JS directly from images or videos.
- Spatial Perception: Judges object positions, viewpoints, and occlusions. Supports 2D grounding and enables 3D grounding for spatial reasoning and embodied AI.
- Long Context & Video Understanding: Native 256K context, expandable to 1M tokens. Handles books and hours-long video with full recall and second-level indexing.
- Multimodal Reasoning: Excels in STEM and math with causal analysis and evidence-based answers.
- Visual Recognition: Broad-covering pretraining recognizes celebrities, anime, products, landmarks, flora, fauna, and more.
- Expanded OCR: Supports 32 languages (up from 19). Robust under low light, blur, and tilt. Handles rare and ancient characters, jargon, and improves long-document structure parsing.
- Text Understanding: Seamless text–vision fusion yields comprehension on par with pure large language models.
Architecture Highlights
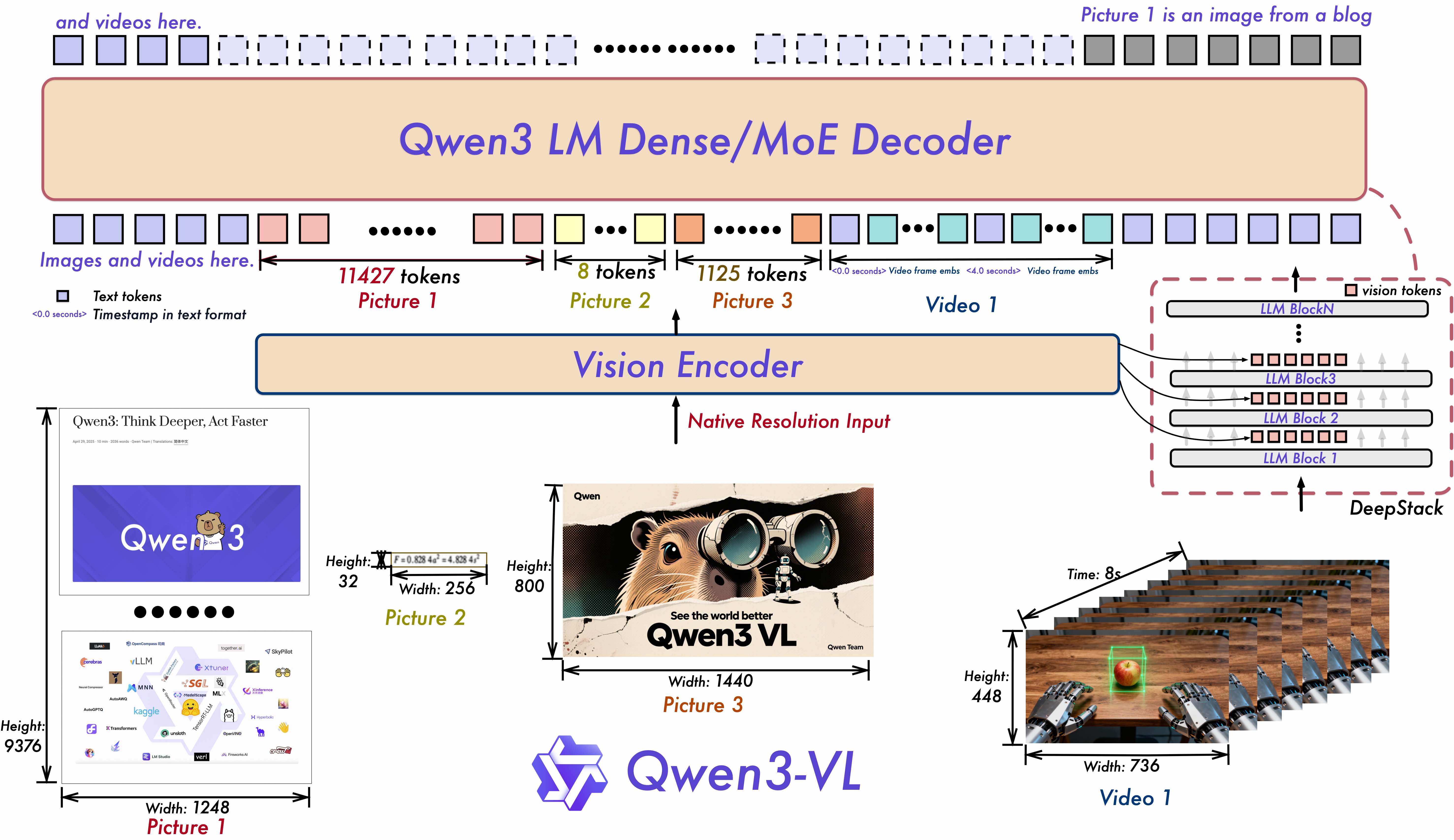
- Interleaved-MRoPE: Full-frequency allocation over time, width, and height for enhanced long-horizon video reasoning.
- DeepStack: Fuses multi-level ViT features to capture fine-grained details and sharpen image–text alignment.
- Text–Timestamp Alignment: Precise, timestamp-grounded event localization for stronger video temporal modeling.
Performance
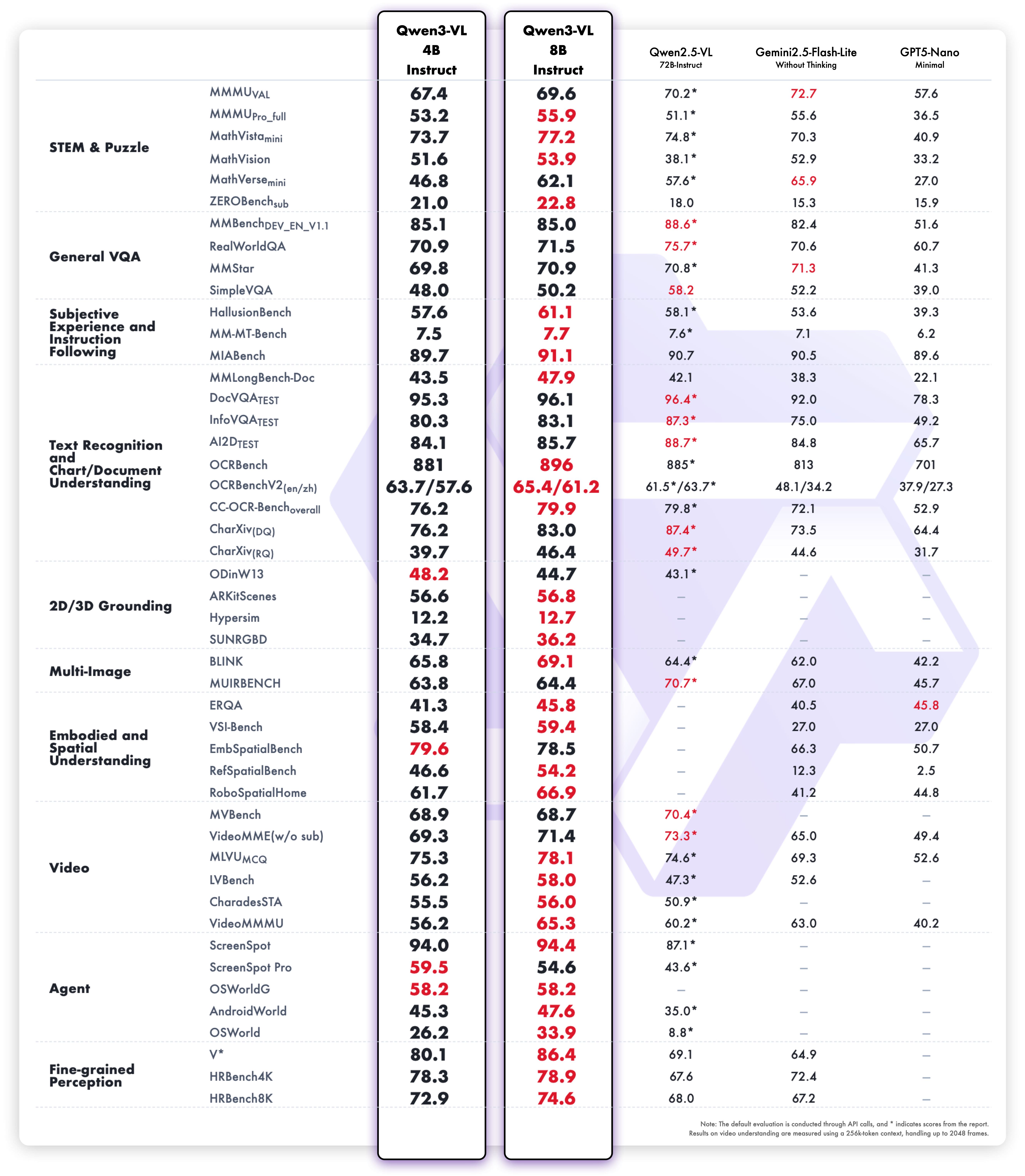
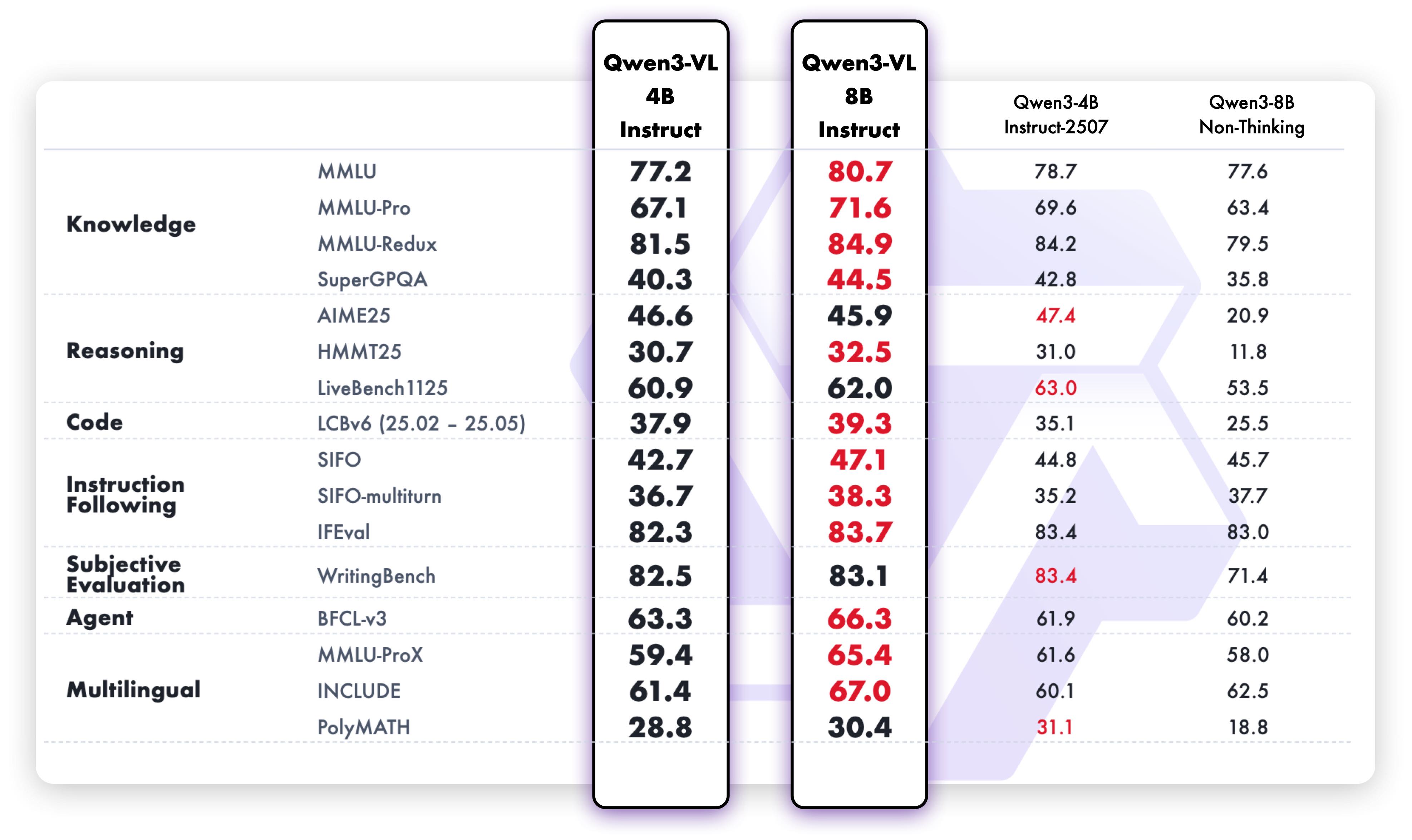
Multimodal and pure text benchmark results are shown below.
not yet live
We're benchmarking and onboarding Qwen3-VL-4B-Instruct as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.