Qwen2.5-VL-3B-Instruct
Qwen/Qwen2.5-VL-3B-Instruct
A popular open vision-language model, with 5.3M downloads a month. gigarouter benchmarks and hosts it as an OpenAI-compatible API.
about this model
Gigarouter hosts Qwen2.5-VL-3B-Instruct, a 3-billion-parameter vision-language model (VLM) designed for multimodal understanding and visual agent tasks. It builds on Qwen2-VL with enhancements in text/chart analysis, long-video comprehension, visual grounding, and structured output generation.
Key Capabilities
- Visual understanding: Recognizes objects, texts, charts, icons, graphics, and layouts within images.
- Agentic use: Functions as a visual agent capable of directing tools, computer use, and phone use.
- Long video comprehension: Processes videos over one hour and pinpoints relevant segments for specific events.
- Visual localization: Generates bounding boxes or points for objects with JSON coordinate outputs.
- Structured outputs: Extracts content from invoices, forms, tables, and similar documents.
Architecture Highlights
Utilizes dynamic resolution and dynamic FPS sampling for video understanding, with updated mRoPE for temporal alignment. The vision encoder integrates window attention, SwiGLU, and RMSNorm for efficiency.
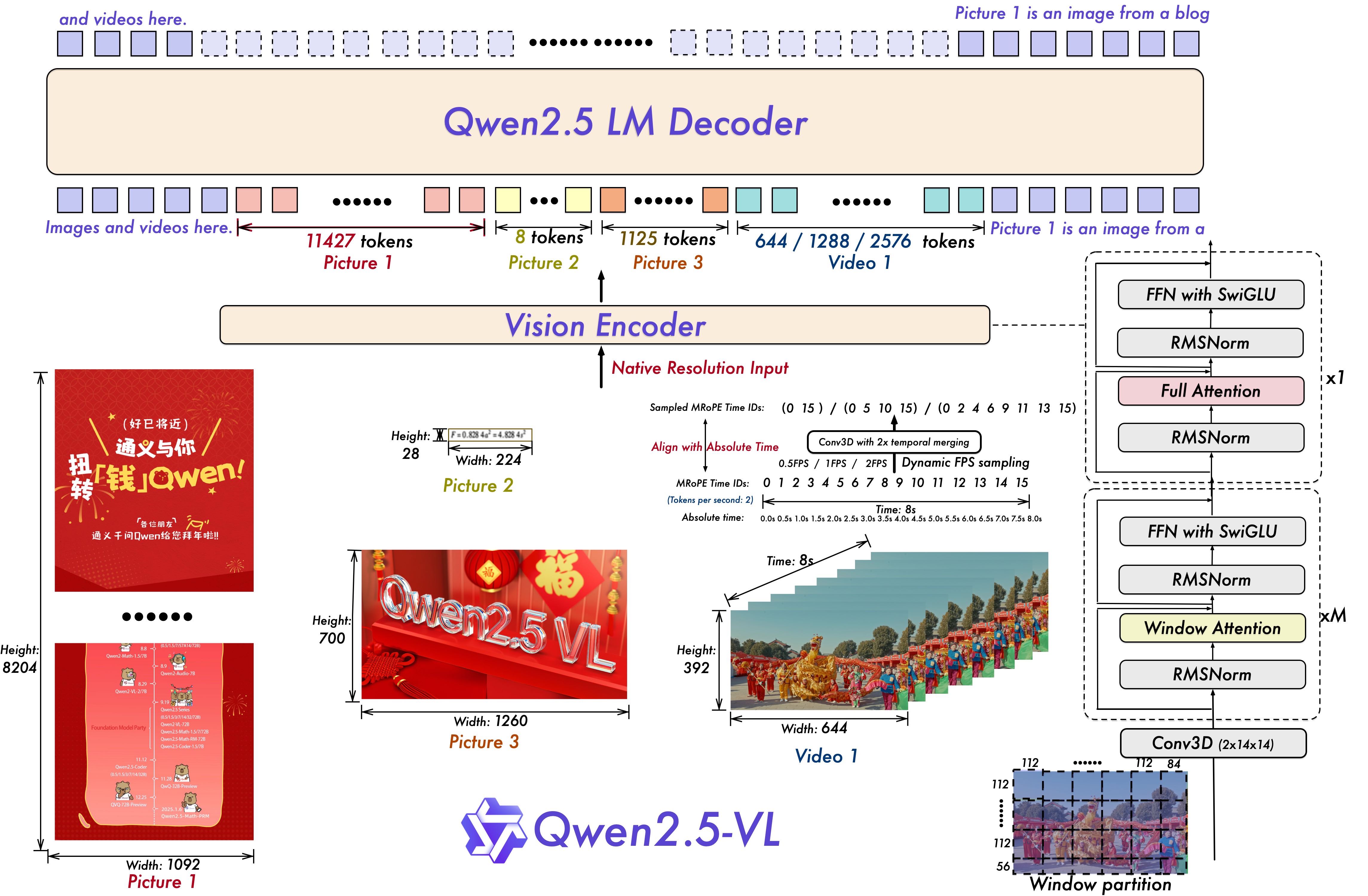
Benchmark Performance
Selected results on image, video, and agent benchmarks:
| Benchmark | Score |
|---|---|
| MMMU (val) | 53.1 |
| DocVQA (test) | 93.9 |
| InfoVQA (test) | 77.1 |
| MathVista (testmini) | 62.3 |
| VideoMME (no subs) | 67.6 |
| MLVU | 68.2 |
| ScreenSpot | 55.5 |
| AndroidWorld (SR) | 90.8 |
| MobileMiniWob++ (SR) | 67.9 |
For detailed comparisons with peer models (InternVL2.5-4B, Qwen2-VL-7B), see the full model card. Further information: Blog and GitHub.
We're benchmarking and onboarding Qwen2.5-VL-3B-Instruct as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.