Chandra
datalab-to/chandra
published Oct 2025 · updated Mar 2026
Chandra is a vlm model that converts images and PDFs into structured markdown, HTML, and JSON with preserved layout.
specs
| Task | OCR (Document Intelligence) |
| Architecture | Vision Language Model (VLM) |
| License | OpenRAIL-M (model), Apache 2.0 (code) |
| Languages | 90+ languages (v2), 40+ languages (v1) |
about this model
Chandra is a visual language model for OCR that converts images and PDFs into structured markdown, HTML, and JSON while preserving layout information.
Key strengths include high-accuracy text extraction with strong handwriting support, accurate form reconstruction (including checkboxes), and robust performance on tables, mathematical expressions, and complex multi-column layouts. The model also extracts images and diagrams with captions and structured data, and supports over 40 languages.
Benchmark Performance
Chandra was evaluated using the olmocr benchmark, which measures OCR accuracy across diverse document types:
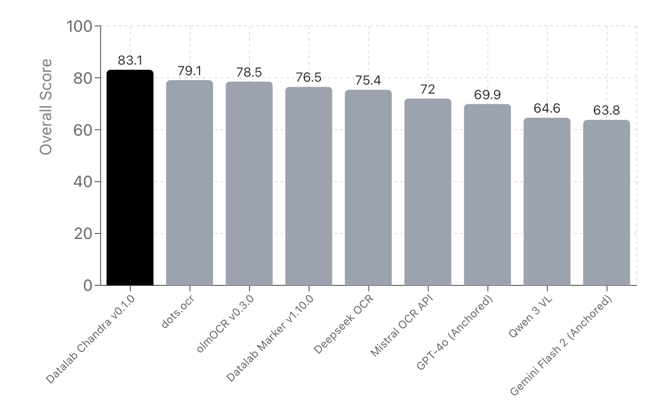
| Model | ArXiv | Old Scans Math | Tables | Old Scans | Headers and Footers | Multi column | Long tiny text | Base | Overall | Source |
|---|---|---|---|---|---|---|---|---|---|---|
| Datalab Chandra v0.1.0 | 82.2 | 80.3 | 88.0 | 50.4 | 90.8 | 81.2 | 92.3 | 99.9 | 83.1 ± 0.9 | Own benchmarks |
| Datalab Marker v1.10.0 | 83.8 | 69.7 | 74.8 | 32.3 | 86.6 | 79.4 | 85.7 | 99.6 | 76.5 ± 1.0 | Own benchmarks |
| Mistral OCR API | 77.2 | 67.5 | 60.6 | 29.3 | 93.6 | 71.3 | 77.1 | 99.4 | 72.0 ± 1.1 | olmocr repo |
| Deepseek OCR | 75.2 | 72.3 | 79.7 | 33.3 | 96.1 | 66.7 | 80.1 | 99.7 | 75.4 ± 1.0 | Own benchmarks |
| GPT-4o (Anchored) | 53.5 | 74.5 | 70.0 | 40.7 | 93.8 | 69.3 | 60.6 | 96.8 | 69.9 ± 1.1 | olmocr repo |
| Gemini Flash 2 (Anchored) | 54.5 | 56.1 | 72.1 | 34.2 | 64.7 | 61.5 | 71.5 | 95.6 | 63.8 ± 1.2 | olmocr repo |
| Qwen 3 VL | 70.2 | 75.1 | 45.6 | 37.5 | 89.1 | 62.1 | 43.0 | 94.3 | 64.6 ± 1.1 | Own benchmarks |
| olmOCR v0.3.0 | 78.6 | 79.9 | 72.9 | 43.9 | 95.1 | 77.3 | 81.2 | 98.9 | 78.5 ± 1.1 | olmocr repo |
| dots.ocr | 82.1 | 64.2 | 88.3 | 40.9 | 94.1 | 82.4 | 81.2 | 99.5 | 79.1 ± 1.0 | dots.ocr repo |
Chandra v0.1.0 achieves an overall score of 83.1 ± 0.9, leading on categories such as Old Scans Math (80.3), Tables (88.0), Old Scans (50.4), Long tiny text (92.3), and Base (99.9).
Example Outputs
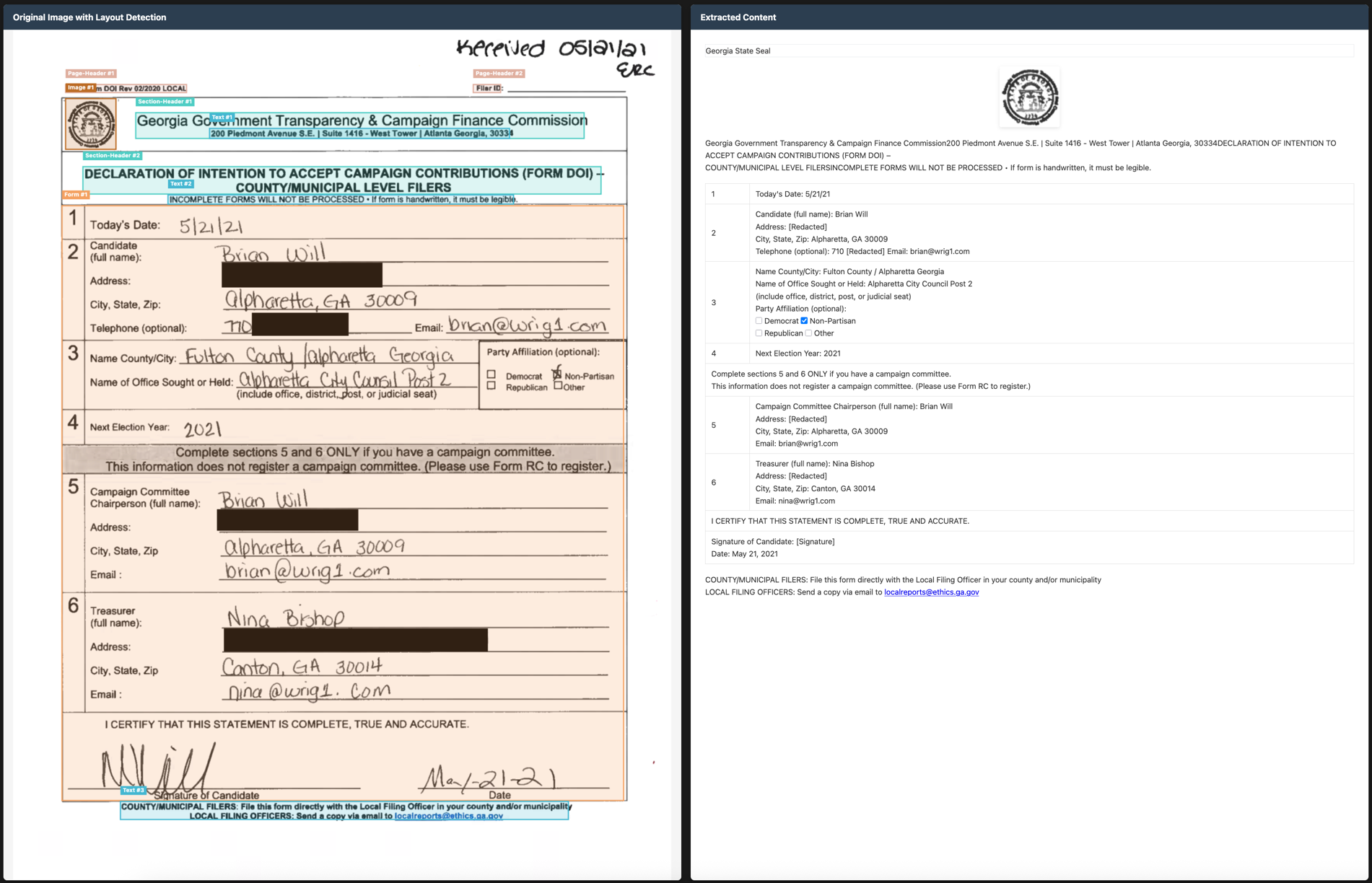
Example conversions for tables, forms, handwriting, books, math, newspapers, and other document types are available in the model repository, demonstrating high-fidelity layout preservation and accurate content extraction.
best for
- ·Extracting text and layout from scanned documents and PDFs
- ·Converting handwritten forms and notes into digital markdown
- ·Extracting tables, math, and complex layouts from images
- ·Multilingual OCR for 90+ languages
FAQ
Chandra outputs markdown, HTML, or JSON with detailed layout information.
Use the OpenAI-compatible endpoint with your API key. Submit an image or PDF and specify the output format.
The model uses OpenRAIL-M; the inference code is Apache 2.0. Commercial self-hosting requires a separate license.
Chandra 2 supports 90+ languages; the earlier version supports 40+.
Yes, for on-prem licensing contact Datalab. A managed API is also available with SOC 2 Type 2 compliance.
We're benchmarking and onboarding Chandra as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.