UI-TARS 7B SFT
ByteDance-Seed/UI-TARS-7B-SFT
published Jan 2025 · updated Jan 2025
UI-TARS 7B SFT is a vision-language model designed for native GUI agent tasks, integrating perception, reasoning, grounding, and memory within a single model.
specs
| Task | GUI Agent / Vision-Language Model |
| Architecture | Qwen2.5-VL-based |
| Parameters | 7B |
| Pipeline | image-text-to-text (Transformers) |
about this model
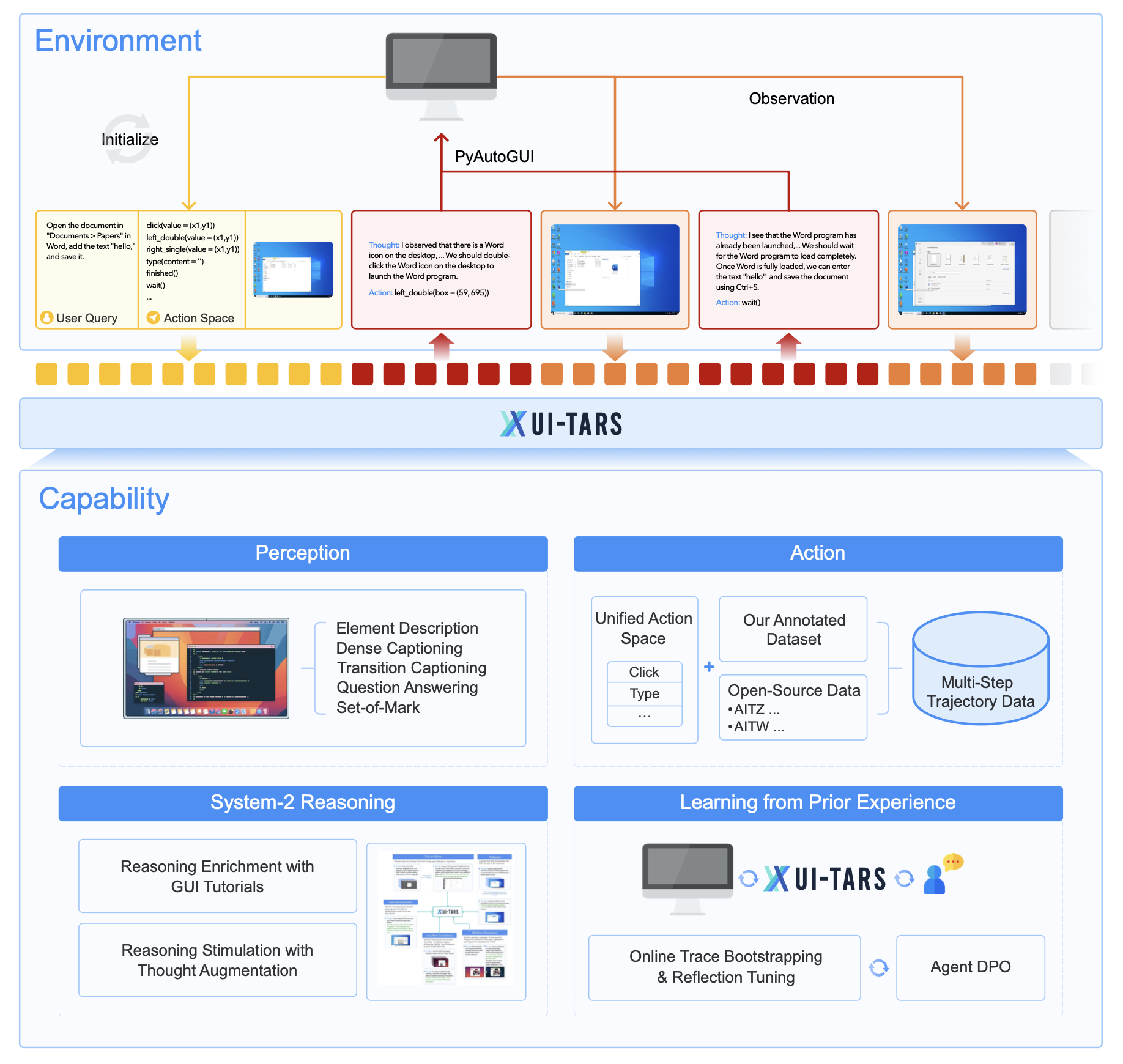
UI-TARS-7B-SFT is a vision-language model (VLM) purpose-built for native GUI agent tasks, enabling direct interaction with graphical user interfaces through human-like perception, reasoning, and action — all from raw screenshot input.
The model integrates perception, grounding, reasoning, and memory into a single end-to-end architecture, eliminating the need for modular frameworks or hand-crafted prompts. Key innovations include context-aware UI understanding via a large-scale screenshot dataset, unified action modeling across platforms, System-2 reasoning (task decomposition, reflection, milestone recognition), and iterative training with reflective online traces on hundreds of virtual machines.
Perception Benchmarks
| Model | VisualWebBench | WebSRC | SQAshort |
|---|---|---|---|
| UI-TARS-7B | 79.7 | 93.6 | 87.7 |
| GPT-4o | 78.5 | 87.7 | 82.3 |
| Claude-3.5-Sonnet | 78.2 | 90.4 | 83.1 |
Grounding & Agent Execution
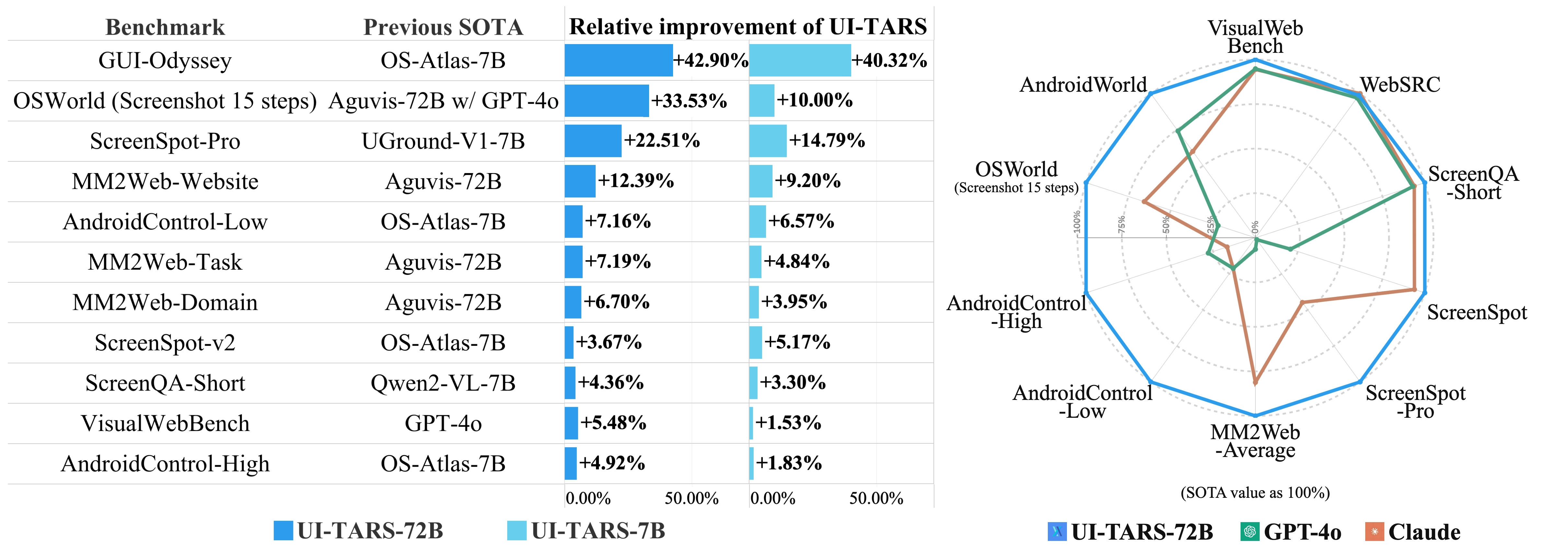
On ScreenSpot v2, UI-TARS-7B achieves an average accuracy of 91.6, outperforming GPT-4o-based frameworks. On Multimodal Mind2Web, it scores 73.1 element accuracy, 92.2 operation F1, and 67.1 step success rate (cross-task). In OSWorld, it reaches 24.6 (50 steps) and 22.7 (15 steps), surpassing Claude (22.0 and 14.9). On AndroidWorld, it achieves 46.6, exceeding GPT-4o (34.5).
The model is built on the Qwen2.5-VL architecture and is hosted by gigarouter as a managed, OpenAI-compatible API — no local setup required.
best for
- ·Automated GUI testing for web, mobile, and desktop applications
- ·End-to-end workflow automation via human-like interaction with interfaces
- ·Building intelligent UI agents that operate on virtual machines
FAQ
It is a vision-language model from ByteDance that acts as a native GUI agent, capable of perceiving screenshots and performing human-like interactions (e.g., mouse, keyboard) to automate tasks across platforms.
It excels at GUI perception, grounding (element localization), and task execution on web, mobile, desktop, and CAD applications. It achieves SOTA on 10+ benchmarks including ScreenSpot, Mind2Web, and OSWorld.
UI-TARS is a single end-to-end model, while frameworks rely on wrapped commercial models. UI-TARS outperforms those frameworks in benchmarks like ScreenSpot-v2 (91.6%) and AndroidControl (high grounding scores).
It uses enhanced perception via large-scale GUI screenshots, unified action modeling across platforms, System-2 reasoning (task decomposition, reflection), and iterative training with reflective online traces on virtual machines.
Use the OpenAI-compatible endpoint provided by gigarouter with your API key. Refer to gigarouter documentation for details on the chat completions interface, system prompt, and image input format.
We're benchmarking and onboarding UI-TARS 7B SFT as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.