Segmentation 3.0
pyannote/segmentation-3.0
published Sep 2023 · updated May 2024
Segmentation 3.0 is a voice-activity-detection model that outputs speaker diarization as a powerset multi-class matrix for 10-second audio chunks.
specs
| Task | Voice Activity Detection, Speaker Segmentation |
| Architecture | Powerset multi-class neural network with pyannote.audio |
| Input | 10 seconds mono audio at 16kHz |
| Output | (num_frames, 7) matrix with non-speech and speaker combinations |
| License | MIT |
about this model
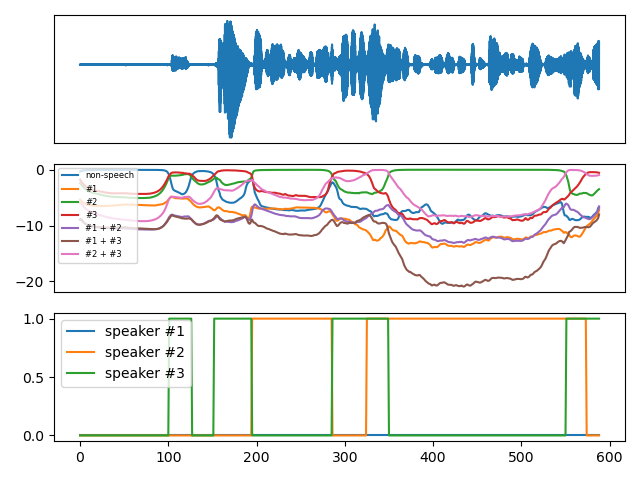
pyannote/segmentation-3.0 is a voice activity detection model that processes 10-second mono audio chunks at 16 kHz and outputs a (num_frames, 7) powerset multi-class encoding, where the seven classes represent non-speech, individual speakers (1–3), and overlapping speaker pairs (1+2, 1+3, 2+3). This enables both voice activity detection (VAD) and overlapped speech detection directly from the same output.
Key strengths
Trained on a large, diverse combination of nine datasets: AISHELL, AliMeeting, AMI, AVA-AVD, DIHARD, Ego4D, MSDWild, REPERE, and VoxConverse. The model is the backbone of the pyannote/speaker-diarization-3.0 pipeline, which achieves state-of-the-art diarization error rates (DER) across 12 benchmark datasets:
| Dataset | DER (%) |
|---|---|
| AISHELL-4 | 12.2 |
| AliMeeting (ch1) | 24.5 |
| AMI IHM | 18.8 |
| AMI SDM | 22.7 |
| AVA-AVD | 49.7 |
| CALLHOME part 2 | 28.5 |
| DIHARD 3 full | 21.4 |
| Ego4D dev | 51.2 |
| MSDWild | 25.4 |
| RAMC | 22.2 |
| REPERE phase2 | 7.9 |
| VoxConverse v0.3 | 11.2 |
Inference is efficient: the full speaker diarization pipeline (including clustering) processes a one-hour recording in approximately 1.5 minutes on a single Nvidia Tesla V100 GPU (real-time factor ~2.5%).
The model is released under the MIT license and is described in detail in the INTERSPEECH 2023 paper “Powerset multi-class cross entropy loss for neural speaker diarization” (Plaquet & Bredin).
best for
- ·Real-time voice activity detection in meetings
- ·Overlapped speech detection in multi-speaker recordings
- ·Building speaker diarization pipelines for full recordings
FAQ
It accepts 10 seconds of mono audio sampled at 16kHz, typically as a waveform tensor.
It uses a powerset multi-class approach to also detect overlapping speakers, not just speech/non-speech.
It is licensed under the MIT license.
Not directly; it processes only 10-second chunks. Use the pyannote/speaker-diarization-3.0 pipeline for full recordings.
Use the OpenAI-compatible endpoint with your gigarouter API key and send audio data as specified in the documentation.
We're benchmarking and onboarding Segmentation 3.0 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.