Nemotron Labs TwoTower 30B A3B
nvidia/Nemotron-Labs-TwoTower-30B-A3B-Base-BF16
published Apr 2026 · updated Jul 2026
Nemotron Labs TwoTower 30B A3B is a text-generation model that uses block-wise autoregressive diffusion, generating text by iteratively denoising blocks of tokens in parallel.
specs
| Task | Text Generation |
| Architecture | Two-Tower Block-Diffusion over Mamba2-Transformer Hybrid Mixture of Experts (MoE) |
| Parameters | ~60B total (30B AR/context tower + 30B diffusion/denoiser tower) |
| License | NVIDIA Nemotron Open Model License |
about this model
Key Capabilities and Architecture
- Generation modes: Mask diffusion (block-wise iterative denoising with confidence-based unmasking), Mock-AR (two-tower autoregressive), and standard AR (single tower).
- Parameters: ~60B total (30B per tower), with ~3B active parameters per token via 128 routable experts (6 activated plus 2 shared).
- Training: The denoiser was trained on ~2.1T tokens using a masked-diffusion objective, with the backbone pretrained on 25T tokens. Precision: BF16. Software: Megatron-LM.
- Context length: Up to 128K tokens.
Benchmark Performance
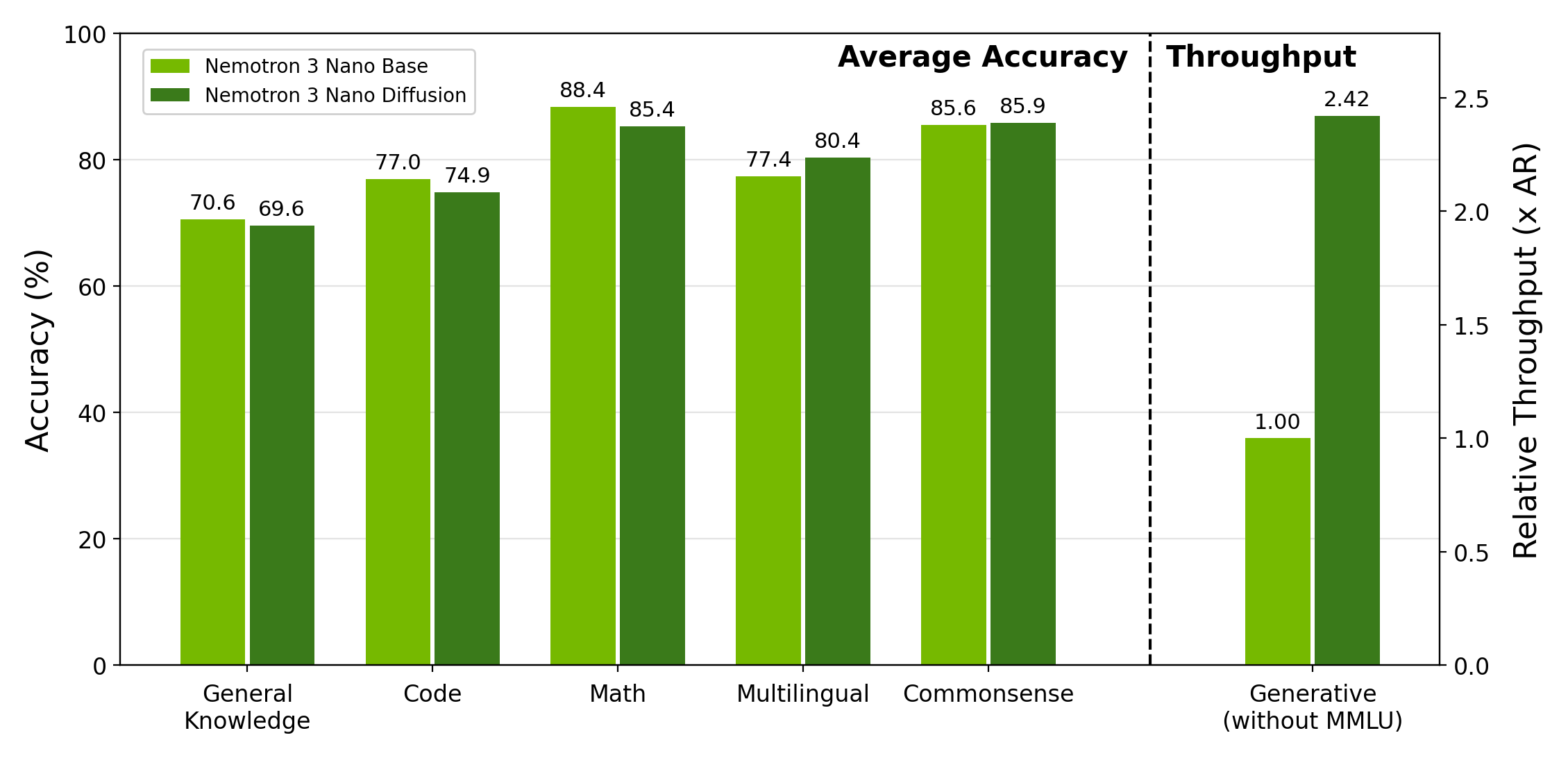
At the default operating point (confidence threshold γ=0.8, block size S=16, BF16 on 2×H100 GPUs), the model retains 98.7% of the autoregressive baseline's aggregate benchmark quality and achieves 2.42× the baseline's wall-clock generation throughput.
| Task | AR Baseline | TwoTower (Diffusion) |
|---|---|---|
| MMLU (5-shot, acc) | 78.56 | 78.24 |
| MMLU-Pro (5-shot, CoT EM) | 62.59 | 60.93 |
| ARC-Challenge (25-shot, acc_norm) | 91.72 | 92.66 |
| WinoGrande (5-shot, acc) | 76.09 | 76.09 |
| RACE (0-shot, acc) | 88.90 | 88.90 |
| HumanEval (0-shot) | 79.27 | 75.58 |
| MBPP-Sanitized (3-shot) | 74.71 | 74.28 |
| GSM8K (8-shot, acc) | 92.49 | 90.14 |
| MATH-500 (4-shot) | 84.40 | 80.60 |
| MMLU Global Lite (5-shot, avg acc) | 73.97 | 73.94 |
| MGSM (8-shot, avg acc) | 80.80 | 80.40 |
How Mask Diffusion Works
Generation is block-wise autoregressive: the context tower encodes the prompt once, then the denoiser fills one block of block_size positions at a time. For each new block, it initializes all positions as [MASK], then for steps_per_block iterations computes the diffusion timestep, runs the denoiser with bidirectional in-block attention and cross-attention to the context cache, and commits high-confidence positions. Multiple tokens may be committed per step.
The model is governed by the NVIDIA Nemotron Open Model License Agreement. Developed by NVIDIA Corporation (September 2025 – April 2026), with pre-training data cutoff June 25, 2025.
best for
- ·Fast parallel text generation with up to 2.42x throughput vs. autoregressive models
- ·Code and math reasoning tasks (HumanEval, GSM8K, MATH)
- ·Long-form generation up to 128K tokens
FAQ
It uses two towers: a frozen autoregressive context tower and a trained diffusion/denoiser tower, both copies of a 52-layer hybrid Mamba-2/attention/MoE backbone. The denoiser generates blocks of tokens via mask diffusion with bidirectional in-block attention and cross-attention to the context tower.
At the default operating point, it retains 98.7% of the autoregressive baseline's quality while providing 2.42x the wall-clock generation throughput, by committing multiple tokens per step.
It is governed by the NVIDIA Nemotron Open Model License Agreement, which permits commercial use.
Input and output are text strings, one-dimensional sequences, with a maximum length of 128K tokens.
Use the OpenAI-compatible gigarouter endpoint with your API key, specifying the model name and your prompt. Refer to gigarouter documentation for request format.
We're benchmarking and onboarding Nemotron Labs TwoTower 30B A3B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.