LocateAnything-3B
nvidia/LocateAnything-3B
A popular open grounding model. gigarouter benchmarks and hosts it as an OpenAI-compatible API.
about this model
Model Overview
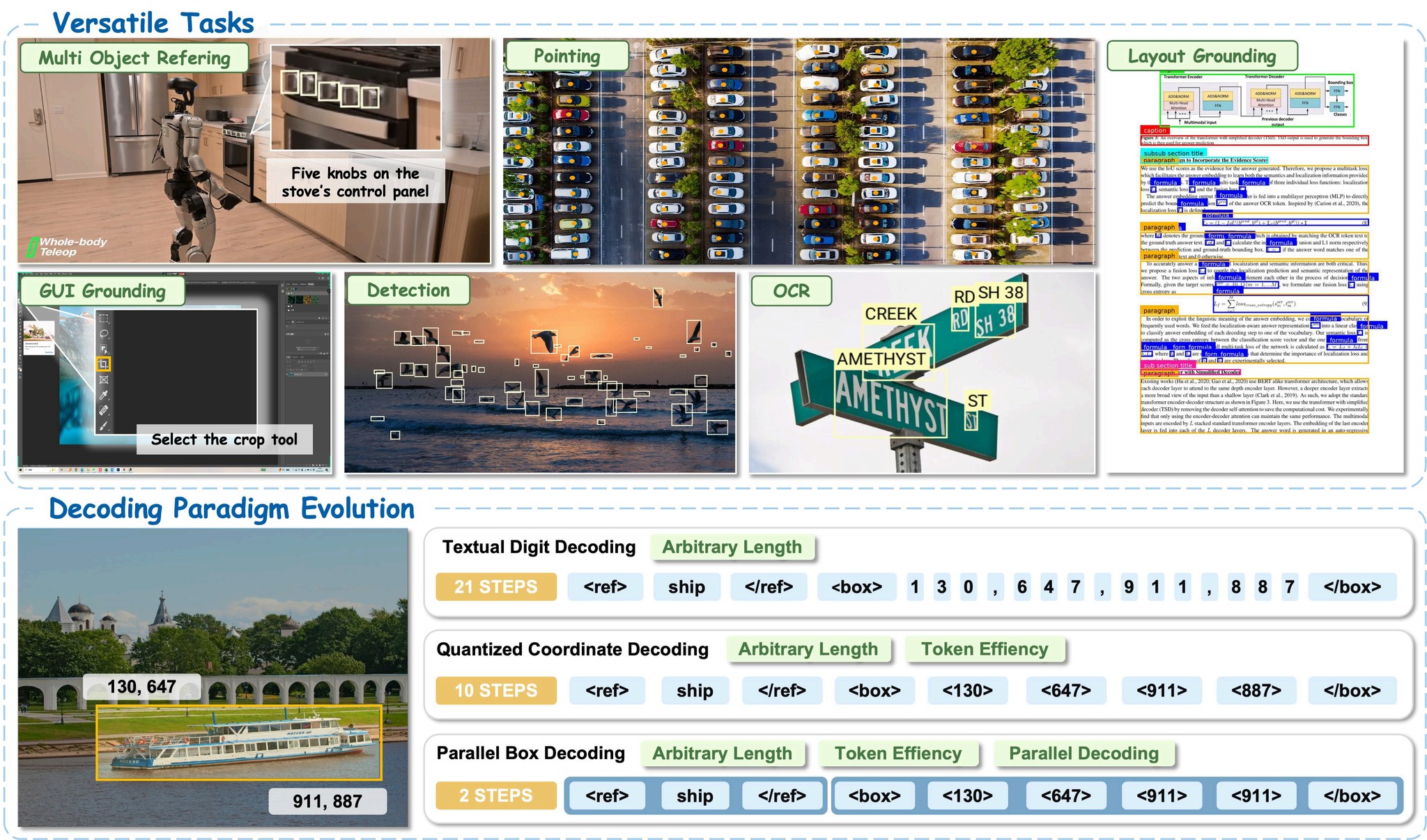
LocateAnything-3B is a vision-language model for fast, high-quality visual grounding. It enables precise object localization, dense detection, and point-based localization across domains including enterprise intelligence and physical AI. The model supports referring expression grounding, multi-object detection, GUI element grounding, and text localization, performing well in complex and cluttered scenes.
Key Innovation
The core innovation is Parallel Box Decoding (PBD), which predicts complete bounding box coordinates in a single parallel step rather than autoregressive token-by-token decoding. This improves efficiency while preserving geometric consistency, enabling up to 2.5× higher throughput compared to prior approaches.
Training and Architecture
LocateAnything-3B is a 3B-parameter transformer-based VLM with a MoonViT vision encoder, Qwen2.5-3B-Instruct language model, and MLP projector. It was trained on a large-scale multi-domain dataset comprising 12M images, 138M+ queries, and 785M bounding boxes spanning natural scenes, robotics, driving, GUI interaction, and document understanding. The model supports native-resolution input up to 2.5K and prompt length up to 24K tokens.
Supported Use Cases
- Open-set, common, and long-tail object detection
- Dense multi-object detection in cluttered scenes
- Phrase and referring-expression grounding
- GUI element grounding for interactive and agentic systems
- Robotics and autonomous driving perception
- Document understanding, layout grounding, and OCR localization
- Point-based localization and fine-grained spatial reasoning
Inference Modes
The same model supports Fast (parallel), Hybrid (parallel with autoregressive fallback), and Slow (autoregressive) inference modes. Hybrid Mode is the default.
License
Released under the NVIDIA License for non-commercial, academic, and research purposes only. Commercial use is not permitted except by NVIDIA and its affiliates.
We're benchmarking and onboarding LocateAnything-3B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.