nomic-embed-text-v1.5
nomic-ai/nomic-embed-text-v1.5
A popular open embeddings model, with 16.9M downloads a month. gigarouter benchmarks and hosts it as an OpenAI-compatible API.
about this model
nomic-embed-text-v1.5 is a text embedding model that produces high-quality vectors for retrieval, clustering, classification, and semantic search. It supports Matryoshka Representation Learning, allowing developers to truncate embeddings to any dimension (64, 128, 256, 512, or 768) with a negligible performance trade-off. The model accepts sequences up to 8,192 tokens.
Task-specific prefixes
To achieve optimal results, prepend the appropriate instruction prefix to each input:
search_document– for documents in a RAG indexsearch_query– for queries to search against a document indexclustering– for grouping texts by topicclassification– for texts used as features in a classifier
Performance
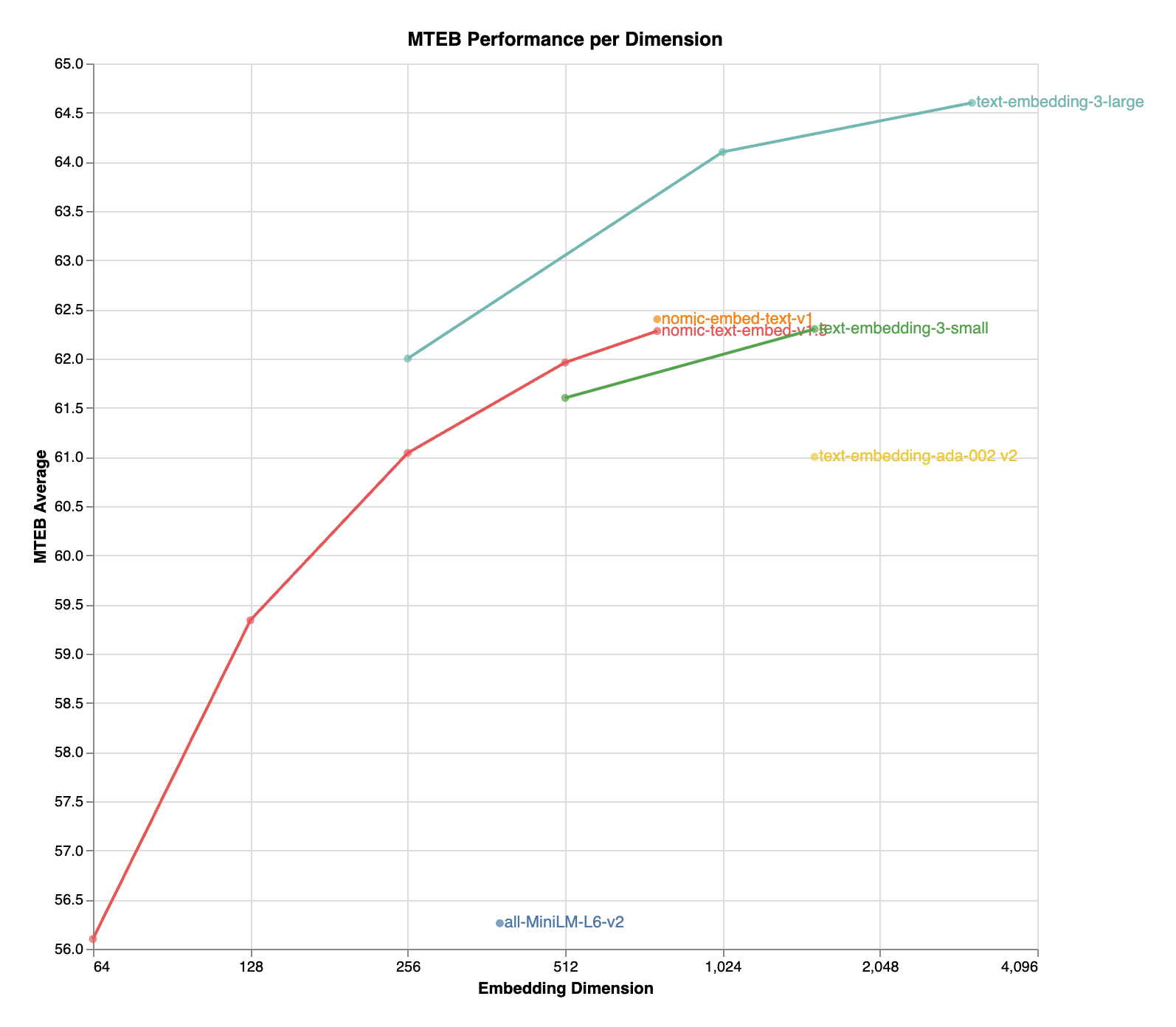
The table below shows MTEB scores at various embedding dimensions. The full 768‑dimension version scores 62.28, while reducing to 512 dimensions retains 61.96.
| Model | Sequence Length | Dimension | MTEB |
|---|---|---|---|
| nomic-embed-text-v1 | 8192 | 768 | 62.39 |
| nomic-embed-text-v1.5 | 8192 | 768 | 62.28 |
| nomic-embed-text-v1.5 | 8192 | 512 | 61.96 |
| nomic-embed-text-v1.5 | 8192 | 256 | 61.04 |
| nomic-embed-text-v1.5 | 8192 | 128 | 59.34 |
| nomic-embed-text-v1.5 | 8192 | 64 | 56.10 |
Text embeddings from this model can also be used alongside the companion vision model nomic-embed-vision-v1.5, which is aligned to the same embedding space.
We're benchmarking and onboarding nomic-embed-text-v1.5 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.