donut-base
naver-clova-ix/donut-base
A popular open image-to-text model, with 166K downloads a month. gigarouter benchmarks and hosts it as an OpenAI-compatible API.
about this model
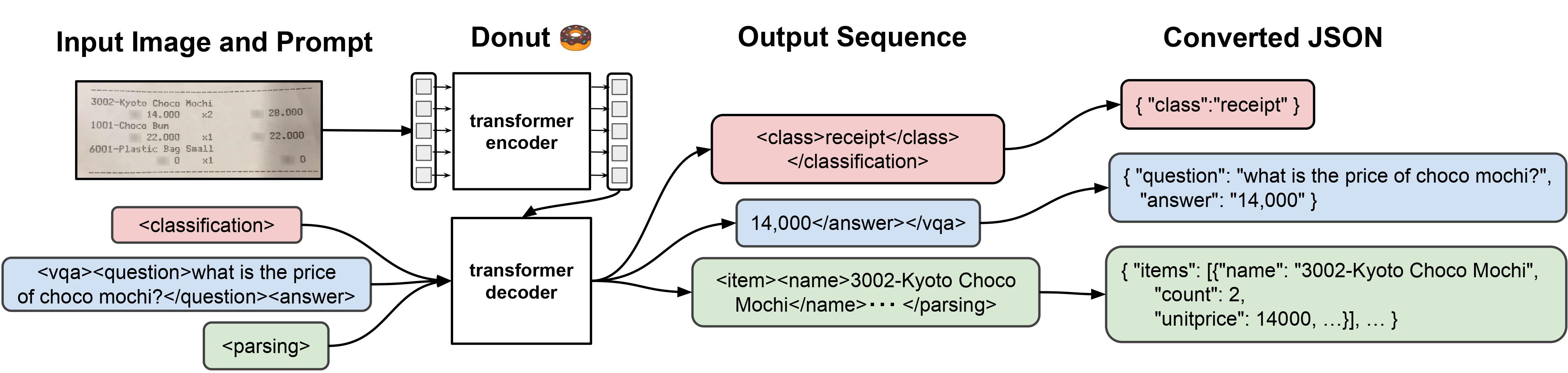
naver-clova-ix/donut-base is an image-to-text model that performs OCR-free document understanding. It combines a Swin Transformer vision encoder with a BART text decoder to directly generate text from images without requiring an external OCR system.
Architecture
The model encodes an image into a sequence of embeddings via the Swin Transformer, then autoregressively decodes text conditioned on those embeddings. This end-to-end design eliminates the need for separate OCR pipelines.
Intended Use
This pre-trained checkpoint is designed to be fine-tuned on downstream tasks such as document image classification, document parsing, and key information extraction. It is the foundation model behind the Donut (Document Understanding Transformer) approach introduced in the paper OCR-free Document Understanding Transformer.
Strengths
- No OCR dependency — reduces error propagation and simplifies deployment.
- Unified architecture for diverse document understanding tasks after fine-tuning.
- Pre-trained on a large corpus of document images, enabling strong transfer learning.
Limitations
As a pre-trained-only model, it is not ready for production use without fine-tuning on a specific task. Performance varies by downstream dataset and fine-tuning regimen.
Availability via gigarouter
gigarouter hosts this model as a managed, OpenAI-compatible API. Users send image data via a standard API call and receive generated text — no model loading, dependencies, or infrastructure management required.
We're benchmarking and onboarding donut-base as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.