wavlm-large
microsoft/wavlm-large
A popular open embeddings model, with 1.4M downloads a month. gigarouter benchmarks and hosts it as an OpenAI-compatible API.
about this model
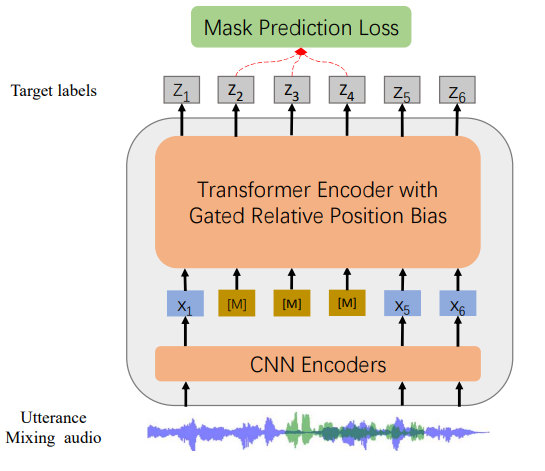
Microsoft's WavLM-Large is a self-supervised speech encoder pre-trained on 94,000 hours of English speech audio sampled at 16 kHz. The training data comprises 60,000 hours from Libri-Light, 10,000 hours from GigaSpeech, and 24,000 hours from VoxPopuli. Built on the HuBERT framework, the model incorporates gated relative position bias in its Transformer structure and an utterance mixing training strategy to improve both spoken content modeling and speaker identity preservation.
Key Capabilities
- Generates speech representations (embeddings) suitable for a full stack of downstream tasks: speech recognition, audio classification, speaker verification, and speaker diarization.
- Achieves state-of-the-art performance on the SUPERB benchmark for universal speech processing evaluation.
- Designed as a general-purpose pre-trained encoder; for task-specific use (e.g., ASR or classification), the model must be fine-tuned with labeled data and a suitable tokenizer.
The model was introduced in the paper WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing and is released under the license found here.
We're benchmarking and onboarding wavlm-large as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.