llava-1.5-7b-hf
llava-hf/llava-1.5-7b-hf
A popular open vision-language model, with 3.2M downloads a month. gigarouter benchmarks and hosts it as an OpenAI-compatible API.
about this model
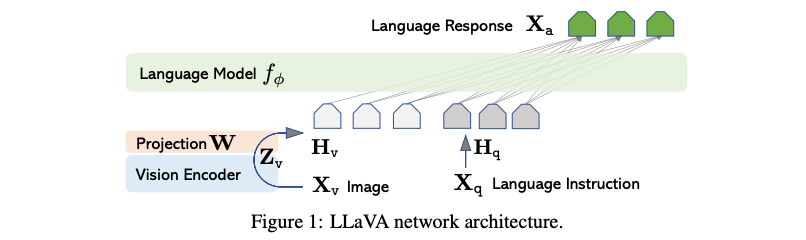
LLaVA-1.5-7B is a vision-language model that processes images and text to generate multimodal responses, fine-tuned from LLaMA/Vicuna on GPT-generated instruction-following data. It is an auto-regressive transformer-based chatbot trained in September 2023.
Capabilities
The model supports multi-image and multi-prompt generation, allowing multiple images to be included in a single conversation. It requires a specific prompt template (USER: xxx\nASSISTANT:) with <image> tokens placed where visual input is queried.
Ideal Use Cases
- Visual question answering (VQA)
- Image captioning and description
- Multimodal dialogue that combines text and visual context
Performance
Benchmark numbers are not provided in the model card. For detailed evaluation results, refer to the original LLaVA publication at llava-vl.github.io.
We're benchmarking and onboarding llava-1.5-7b-hf as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.