LightOnOCR-1B-1025
lightonai/LightOnOCR-1B-1025
A popular open image-to-text model, with 199.9K downloads a month. gigarouter benchmarks and hosts it as an OpenAI-compatible API.
about this model
LightOnOCR-1B-1025 is an image-to-text model for Optical Character Recognition (OCR) and document understanding. It is a compact, end-to-end vision–language model that achieves state-of-the-art accuracy in its weight class while being several times faster and cheaper than larger general-purpose VLMs.
Key Strengths
- Speed: 5× faster than dots.ocr, 2× faster than PaddleOCR-VL-0.9B, 1.73× faster than DeepSeekOCR.
- Efficiency: Processes 5.71 pages per second on a single H100 (approximately 493k pages per day) for less than $0.01 per 1,000 pages.
- End-to-End: Fully differentiable, no external OCR pipeline required.
- Versatile: Handles tables, receipts, forms, multi-column layouts, and mathematical notation.
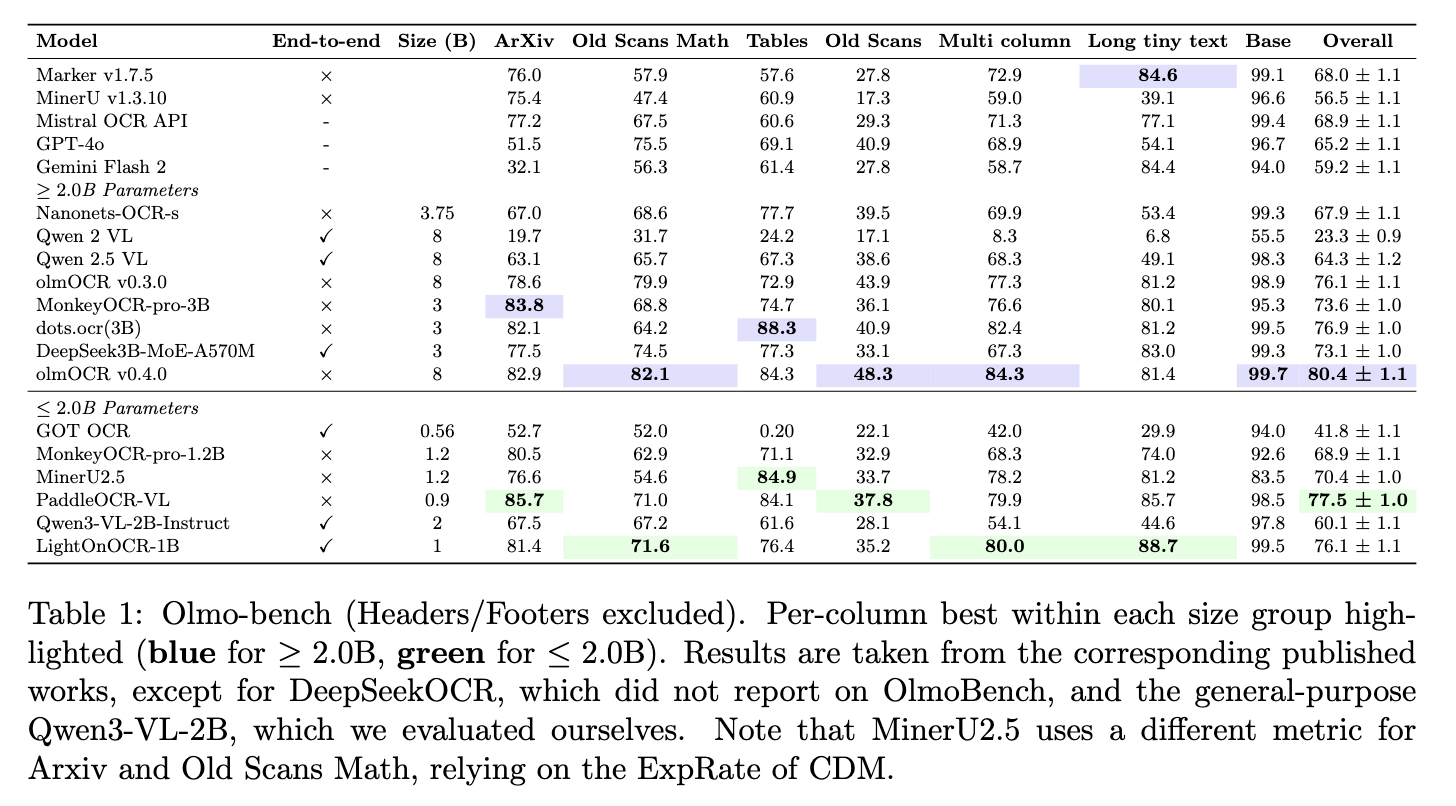
Benchmark Results
All benchmarks evaluated using vLLM on the Olmo-Bench.
Variants
This model is the full BF16 version recommended for inference. LightOnOCR is also available in pruned-vocabulary variants for faster processing in European languages.
| Variant | Description |
|---|---|
| LightOnOCR-1B-1025 | Full multilingual model (default) |
| LightOnOCR-1B-32k | Fastest pruned-vocabulary version (32k tokens) optimized for European languages |
| LightOnOCR-1B-16k | Most compact variant with smallest vocabulary |
For best results, render PDFs to PNG or JPEG at a target longest dimension of 1540px while maintaining aspect ratio.
We're benchmarking and onboarding LightOnOCR-1B-1025 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.