jina-embeddings-v2-small-en
jinaai/jina-embeddings-v2-small-en
A popular open embeddings model, with 1.3M downloads a month. gigarouter benchmarks and hosts it as an OpenAI-compatible API.
about this model
jina-embeddings-v2-small-en is an English monolingual embedding model hosted on gigarouter. It is based on a BERT architecture (JinaBERT) with symmetric bidirectional ALiBi, enabling a maximum sequence length of 8192 tokens despite being trained on 512-length sequences. The model has 33 million parameters, supporting fast and memory-efficient inference.
Key Strengths
- Supports up to 8192 token sequence length, suitable for long documents.
- 33M parameters for low-latency, memory-efficient deployment.
- Pretrained on C4 and fine-tuned on over 400 million sentence pairs with hard negatives from diverse domains.
Best For
- Long document retrieval
- Semantic textual similarity
- Text reranking and recommendation
- RAG and LLM-based generative search
Benchmark Performance
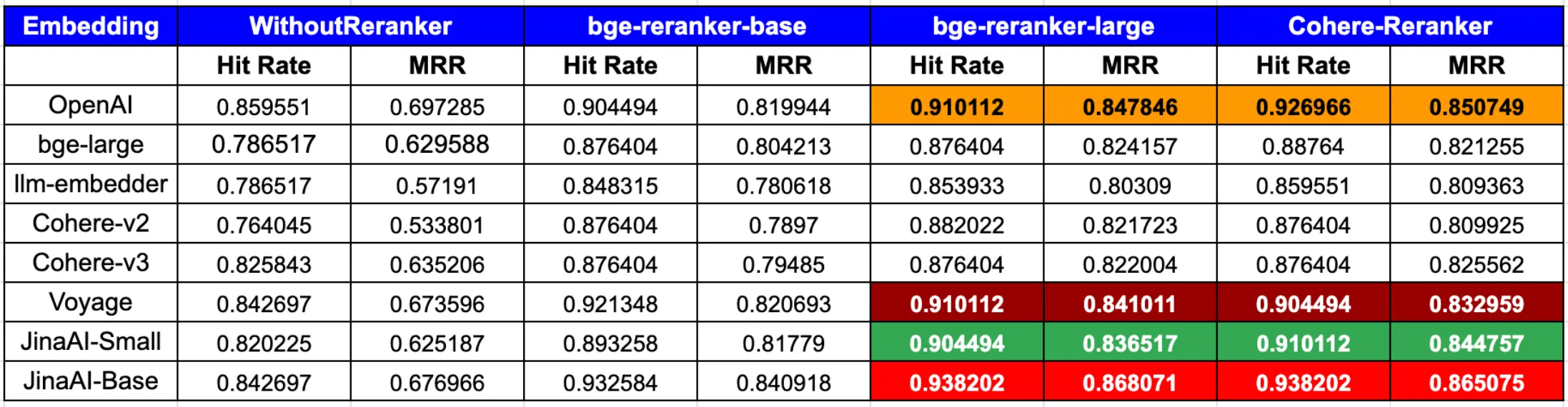
According to LlamaIndex, to achieve peak performance in both hit rate and MRR, the combination of OpenAI or JinaAI-Base embeddings with CohereRerank or bge-reranker-large rerankers stands out.
Model Variants
| Model | Parameters | Languages |
|---|---|---|
| jina-embeddings-v2-small-en | 33M | English |
| jina-embeddings-v2-base-en | 137M | English |
| jina-embeddings-v2-base-zh | 161M | Chinese-English bilingual |
| jina-embeddings-v2-base-de | 161M | German-English bilingual |
Technical details are available in the Jina Embeddings V2 paper.
We're benchmarking and onboarding jina-embeddings-v2-small-en as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.