siglip2-base-patch16-224
google/siglip2-base-patch16-224
A popular open zero-shot image model, with 408.5K downloads a month. gigarouter benchmarks and hosts it as an OpenAI-compatible API.
about this model
SigLIP 2 is a vision-language encoder designed for zero-shot image classification and image-text retrieval, and can also serve as a vision encoder for vision-language models (VLMs). It extends the SigLIP pretraining objective with decoder loss, global-local and masked prediction loss, and aspect ratio and resolution adaptability, resulting in improved semantic understanding, localization, and dense feature quality.
Capabilities
- Zero-shot image classification
- Image-text retrieval
- Vision encoder for VLMs and other vision tasks
Training
Pre-trained on the WebLI dataset (Chen et al., 2023). Training used up to 2048 TPU-v5e chips.
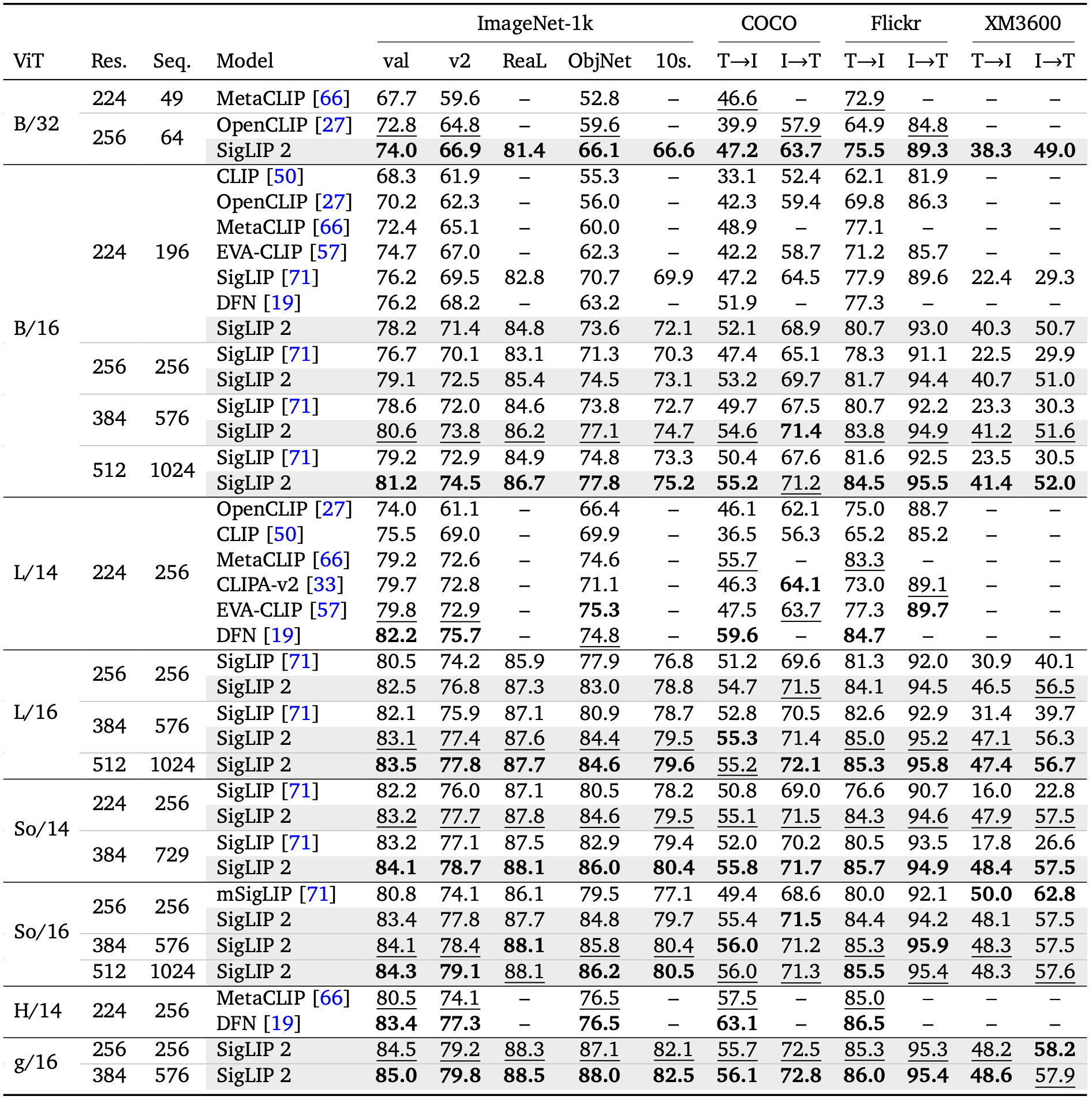
Benchmarks
Evaluation results from the SigLIP 2 paper are shown below.
We're benchmarking and onboarding siglip2-base-patch16-224 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.