DeepSeek-OCR-2
deepseek-ai/DeepSeek-OCR-2
A popular open vision-language model, with 3.3M downloads a month. gigarouter benchmarks and hosts it as an OpenAI-compatible API.
about this model
DeepSeek-OCR 2 is a vision-language model (VLM) specialized for optical character recognition (OCR) and document understanding. It processes images and natural language prompts to extract text, with a primary focus on converting documents to structured markdown or performing free-form OCR. The model introduces a "Visual Causal Flow" architecture designed to achieve more human-like visual encoding.
Capabilities
- Document OCR with layout-aware markdown output via the
<image>\n<|grounding|>Convert the document to markdown.prompt. - Free OCR without layout information using the
<image>\nFree OCR.prompt. - Dynamic resolution support: default configuration uses (0–6)×768×768 tiles plus one 1024×1024 tile, yielding (0–6)×144 + 256 visual tokens.
Best For
Developers needing high-quality, prompt-controlled OCR from images of documents, tables, or forms, especially when retaining spatial layout in markdown output is required.
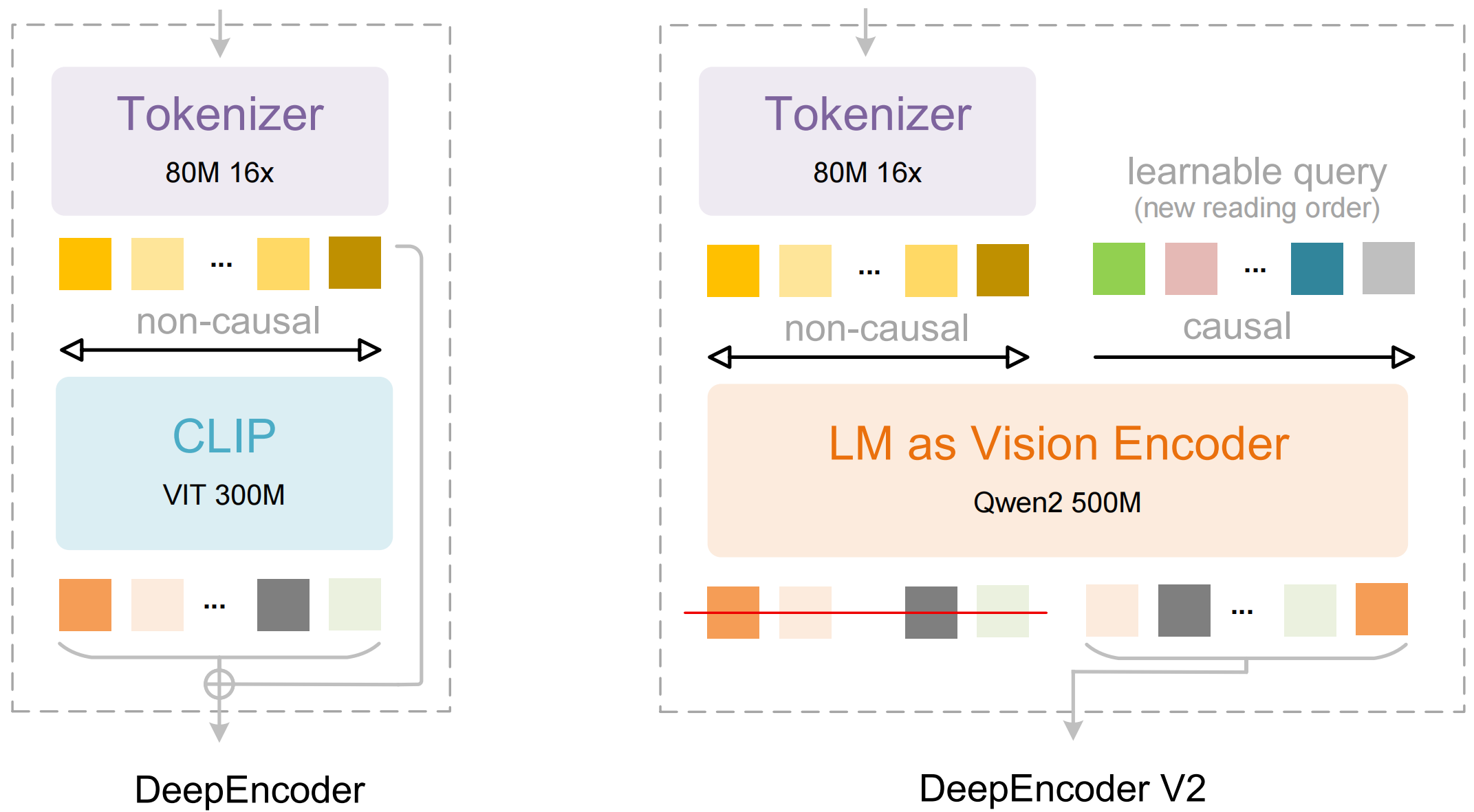
For further details, refer to the arXiv paper and the GitHub repository.
We're benchmarking and onboarding DeepSeek-OCR-2 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.