Qwen2-VL-2B-Instruct
Qwen/Qwen2-VL-2B-Instruct
A popular open vision-language model, with 3.6M downloads a month. gigarouter benchmarks and hosts it as an OpenAI-compatible API.
about this model
Qwen2-VL-2B-Instruct is a vision-language model (VLM) that processes images, multilingual text within images, and videos up to 20 minutes, and can be integrated with devices such as mobile phones and robots for visual-based decision-making.
Key Strengths
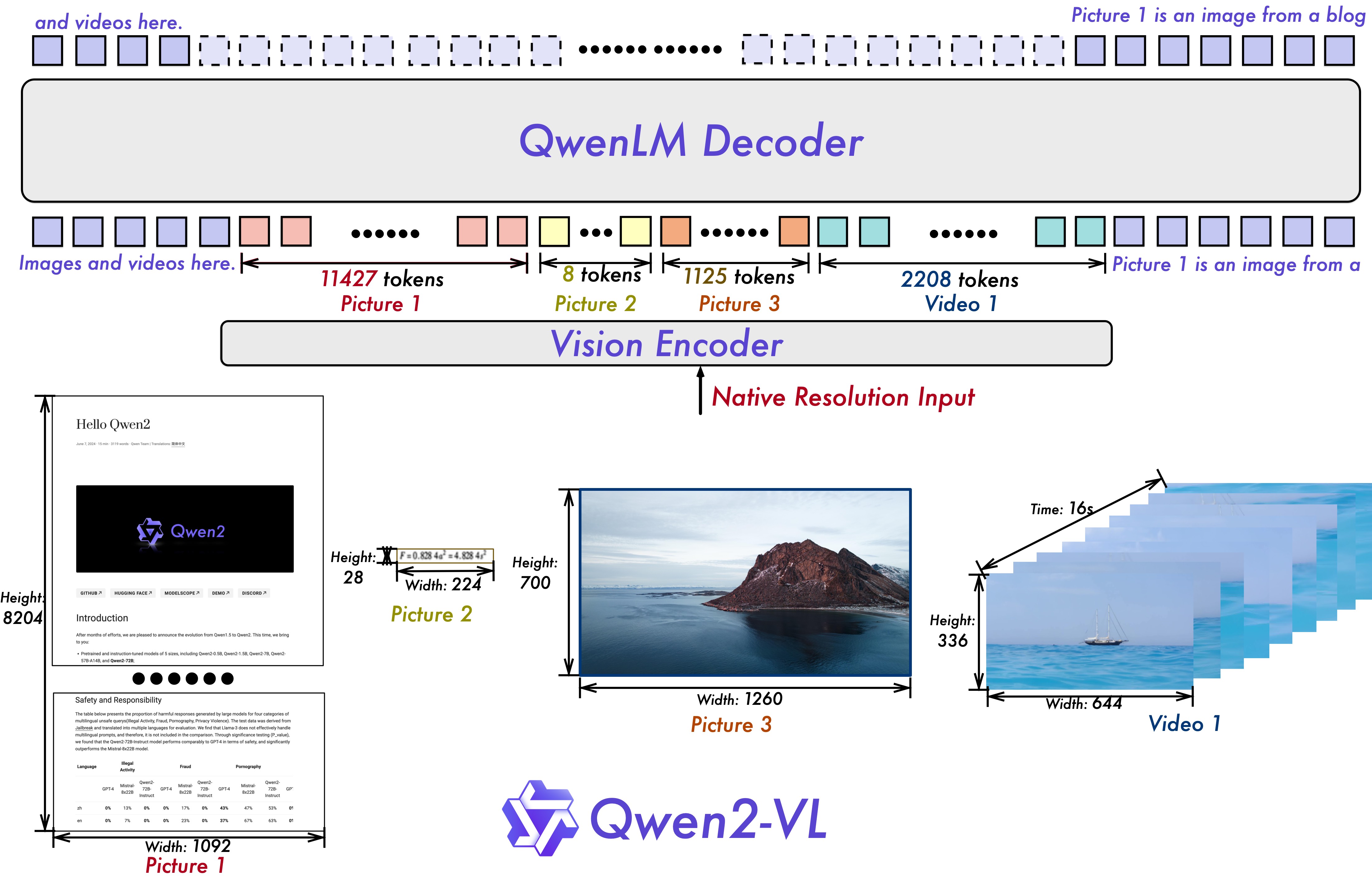
- State-of-the-art understanding across diverse image resolutions and aspect ratios, enabled by Naive Dynamic Resolution.
- Multimodal Rotary Position Embedding (M-ROPE) captures 1D text, 2D image, and 3D video positional information for enhanced multimodal processing.
- Supports text in multiple languages (European languages, Japanese, Korean, Arabic, Vietnamese, etc.) inside images.
- Capable of long-form video understanding for QA, dialog, and content creation.

Benchmark Performance
| Benchmark | Qwen2-VL-2B | InternVL2-2B | MiniCPM-V 2.0 |
|---|---|---|---|
| MMMU | 41.1 | 36.3 | 38.2 |
| DocVQA | 90.1 | 86.9 | - |
| InfoVQA | 65.5 | 58.9 | - |
| ChartQA | 73.5 | 76.2 | - |
| TextVQA | 79.7 | 73.4 | - |
| OCRBench | 794 | 781 | 605 |
| RealWorldQA | 62.9 | 57.3 | 55.8 |
| MMBench-EN | 74.9 | 73.2 | 69.1 |
| MMVet | 49.5 | 39.7 | 41.0 |
| HallBench | 41.7 | 38.0 | 36.1 |
Video benchmarks (Qwen2-VL-2B only): MVBench 63.2, PerceptionTest 53.9, EgoSchema 54.9, Video-MME 55.6/60.4.
This model is hosted as a managed, OpenAI-compatible API on gigarouter, eliminating setup overhead. Ideal for document analysis, visual question answering, video understanding, and multilingual OCR tasks.
We're benchmarking and onboarding Qwen2-VL-2B-Instruct as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.