ARK-ASR 0.6B
AutoArk-AI/ARK-ASR-0.6B
published May 2026 · updated Jun 2026
ARK-ASR 0.6B is an automatic speech recognition model that uses a compact 0.6B-scale decoder LLM with a Whisper-style audio encoder and on-policy distillation to transcribe speech in 19 languages.
specs
| Task | Automatic Speech Recognition (ASR) |
| Architecture | Audio-capable autoregressive Transformer with Whisper-style encoder, MLP adapter, and Qwen2 decoder |
| Parameters | 0.6B decoder LLM + 0.6B-scale audio encoder |
| License | Apache 2.0 |
about this model
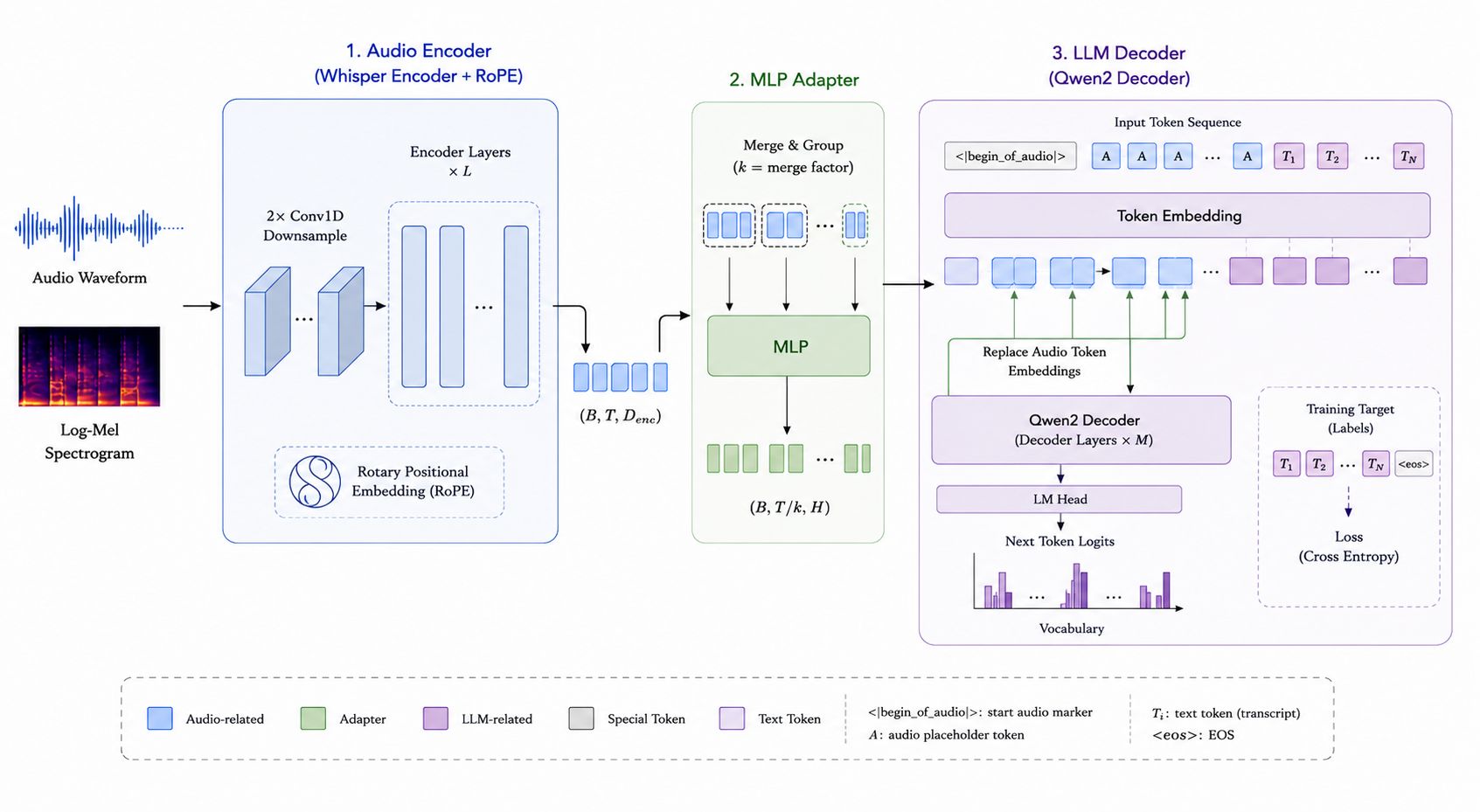
Architecture
Audio is encoded by a Whisper-style encoder with RoPE, merged through an MLP adapter, and injected into a Qwen2 decoder by replacing audio placeholder token embeddings before transcript generation. The model operates at 16 kHz sampling rate and uses autoregressive Transformers with custom arkasr remote code.
Performance
Evaluated across 7 English and 3 Chinese benchmarks, with lower CER/WER being better:
| English WER | AMI | Earnings22 | GigaSpeech | LS Clean | LS Other | SPGISpeech | VoxPopuli | Avg |
|---|---|---|---|---|---|---|---|---|
| Ark-ASR | 11.54% | 10.07% | 8.95% | 1.87% | 3.89% | 2.89% | 6.63% | 6.55% |
| Qwen3-ASR-0.6B | 11.66% | 11.06% | 9.14% | 2.13% | 4.45% | 3.03% | 7.07% | 6.93% |
| Qwen3-ASR-1.7B | 10.56% | 10.25% | 8.74% | 1.63% | 3.40% | 2.84% | 6.35% | 6.25% |
| Chinese CER | AISHELL-1 | Wenet-meeting | Wenet-net | Avg |
|---|---|---|---|---|
| Ark-ASR | 2.02% | 5.92% | 4.96% | 4.30% |
| Qwen3-ASR-0.6B | 2.07% | 5.57% | 5.45% | 4.36% |
| Qwen3-ASR-1.7B | 1.50% | 4.69% | 4.55% | 3.58% |
Ark-ASR achieves an average English WER of 6.55% and Chinese CER of 4.30%, outperforming the same-scale Qwen3-ASR-0.6B baseline (6.93% WER, 4.36% CER) across all reported benchmarks. The model was trained on only 100k hours of speech, compared to the 20M hours used for the Qwen3-Omni AuT encoder. The larger Qwen3-ASR-1.7B remains stronger overall, but the OPD training recipe substantially closes the gap for compact models under a much smaller audio budget.
Methodology
The OPD training recipe uses 4 student rollouts per prompt with a union top-k KL objective, combining teacher top-k and student top-k tokens. The foundational OPD paper has been accepted to ICML 2026 FoGen Workshop. The model is released under the Apache-2.0 license, with the accompanying paper published under CC BY 4.0.
best for
- ·Transcribing multilingual audio in 19 languages including Chinese, English, German, Japanese, and French
- ·Deploying a compact, data-efficient ASR model for production environments with limited compute
- ·Batch transcription of short audio clips (up to 30 seconds) with high accuracy
FAQ
It supports 19 languages: Chinese, English, German, Japanese, French, Korean, Spanish, Polish, Italian, Romanian, Hungarian, Czech, Dutch, Finnish, Croatian, Slovak, Slovene, Estonian, and Lithuanian.
It has a 0.6B-parameter decoder LLM plus a 0.6B-scale audio encoder, making it a compact model that outperforms the same-scale Qwen3-ASR-0.6B on most benchmarks while being much smaller than the 1.7B Qwen3-ASR variant.
The model weights are released under the Apache 2.0 license.
The model expects 16 kHz mono audio. It can be provided as a file path or raw audio array, and the processor handles resampling and padding.
Use the gigarouter OpenAI-compatible endpoint with your API key, sending the audio file or URL in a request formatted for the ASR task.
We're benchmarking and onboarding ARK-ASR 0.6B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.