gte-multilingual-base
Alibaba-NLP/gte-multilingual-base
A popular open embeddings model, with 1.2M downloads a month. gigarouter benchmarks and hosts it as an OpenAI-compatible API.
about this model
The gte-multilingual-base model (305M parameters) produces dense text embeddings with a default dimension of 768 and supports input lengths up to 8,192 tokens. It is designed for multilingual retrieval and representation tasks, covering over 70 languages. The model uses an encoder-only transformer architecture, offering lower inference cost and approximately 10× faster speed compared to decoder-only LLM‑based embedding models of similar capability.
Key Capabilities
- Elastic dense embeddings: output dimension can be reduced to as low as 128 while preserving downstream effectiveness, reducing storage and computation.
- Sparse vector generation: the model can also produce sparse token‑weight vectors for hybrid retrieval.
- Multilingual and cross‑lingual retrieval: evaluated on MIRACL, MLDR, MKQA, BEIR, and LoCo benchmarks.
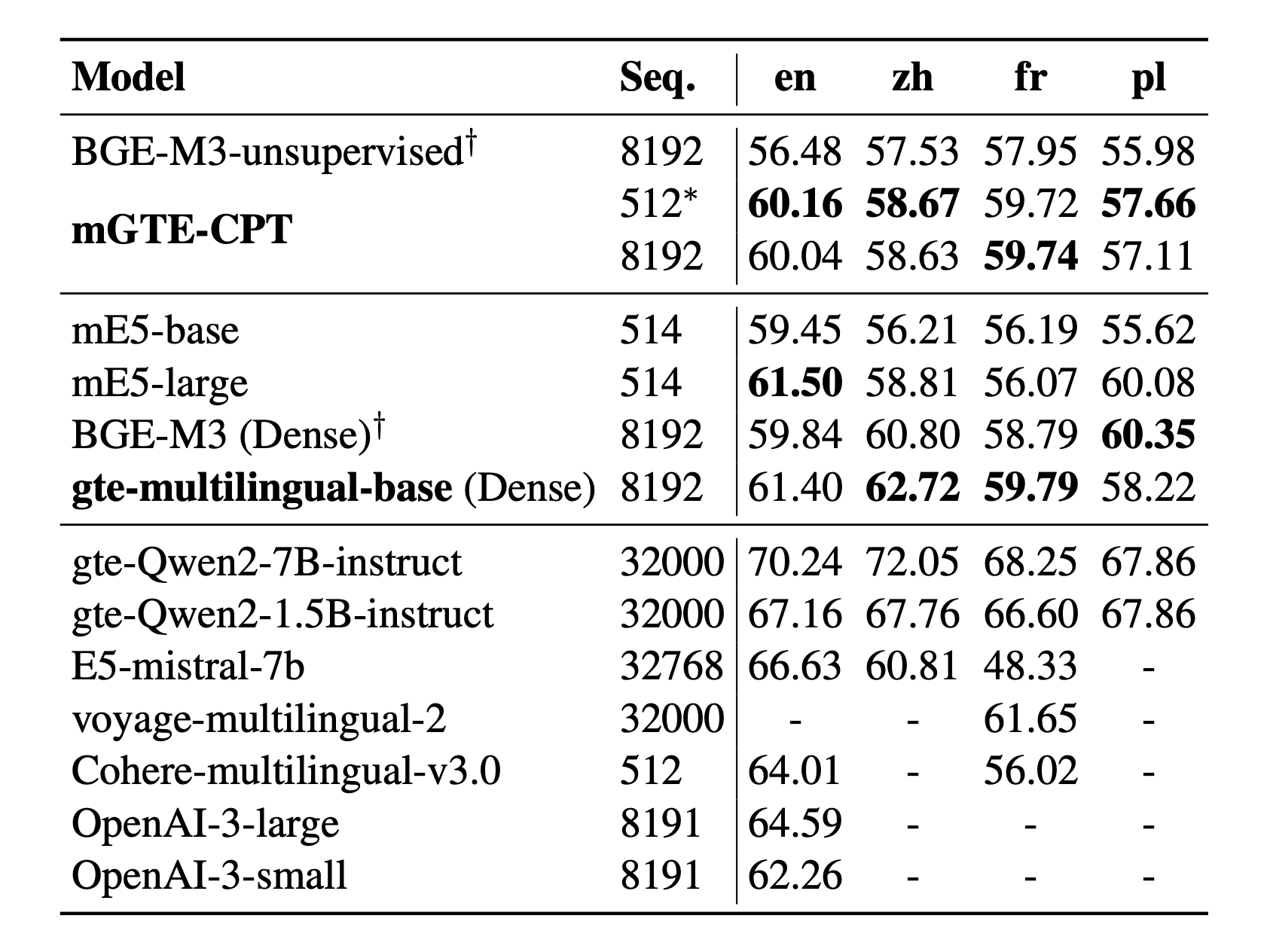
- General text representation: results on MTEB (English, Chinese, French, Polish).
Benchmark Highlights
Achieves state-of-the-art results among models of similar size on multilingual retrieval and multi‑task representation evaluations.
Retrieval performance on MIRACL, MLDR, MKQA, BEIR, and LoCo:
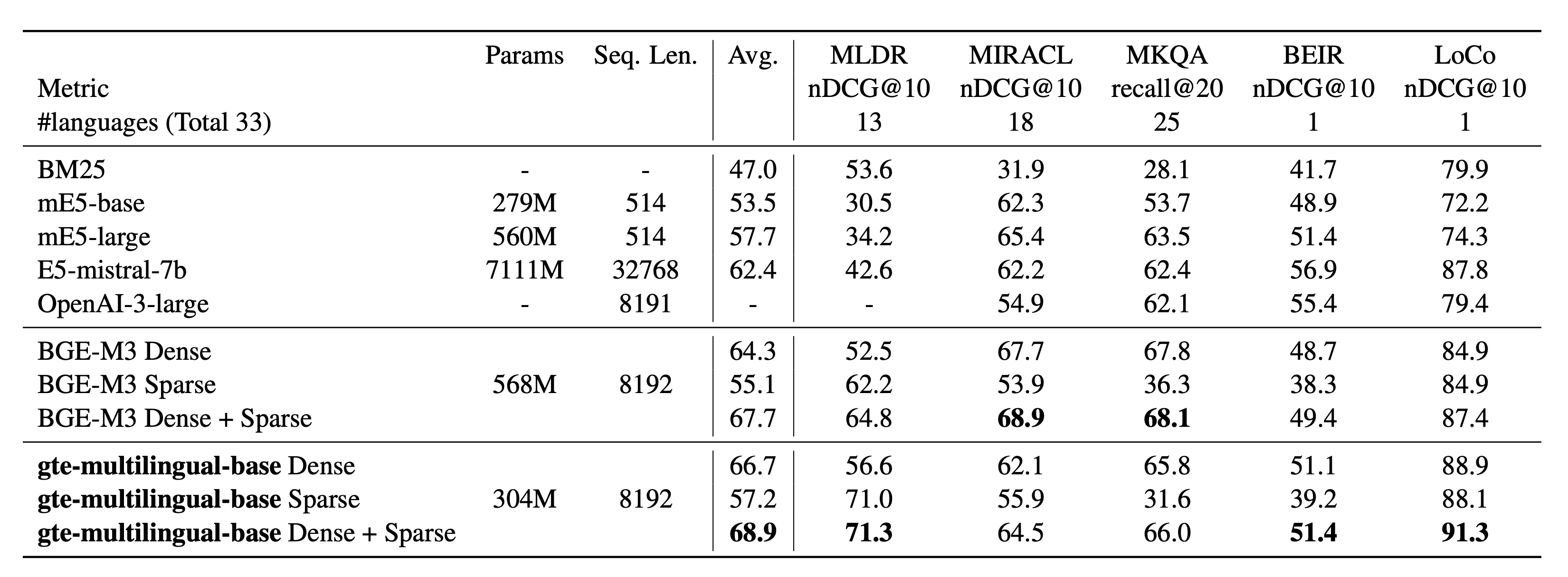
Detailed results on MLDR and LoCo are available in the paper.
MTEB results across languages:
Further Details
For comprehensive experimental results and methodology, see the paper mGTE: Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval.
We're benchmarking and onboarding gte-multilingual-base as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.