Ornith 1.0 35B AEON Ultimate Uncensored
AEON-7/Ornith-1.0-35B-AEON-Ultimate-Uncensored-NVFP4
published Jun 2026 · updated Jun 2026
Ornith 1.0 35B AEON Ultimate Uncensored is an uncensored 4-bit NVFP4 quantized Mixture-of-Experts text-generation model optimized for agentic coding and reasoning.
specs
| Task | Text Generation |
| Architecture | Mixture of Experts (MoE) with GatedDeltaNet and attention |
| Parameters | 35B total |
| Quantization | NVFP4 (4-bit weight-only) / W4A16 |
| License | Custom (see model card for terms) |
about this model
AEON-7/Ornith-1.0-35B-AEON-Ultimate-Uncensored-NVFP4 is a text-generation model that provides a near-lossless 4-bit quantized version of the state-of-the-art agentic-coding MoE, with refusals removed. It uses weight-only NVFP4 (W4A16) to reduce size to 23.7 GB while preserving attention and SSM components in BF16. The model is validated to be coherent and identical in coding capability to its BF16 parent.
Validation
| Metric | BF16 parent | This NVFP4 |
|---|---|---|
| Agentic/coding pass@1 (18-task probe) | 0.833 | 0.833 — identical |
| Refusals (diverse harmful prompts) | 0 | 0 — abliteration fully survived FP4 |
| Coherence (benign + harmful, long gen) | clean | 0/10 degenerate |
Performance on DGX Spark (GB10)
Plain decode (NVFP4, no speculative decoding):
| Concurrency | c=1 | c=8 | c=16 | c=32 |
|---|---|---|---|---|
| aggregate tok/s | 39 | 221 | 376 | 539 |
With DFlash speculative decoding (optimal n=6): single-stream decode reaches 73.8 tok/s (1.89× over plain).
Combined gains vs a naive BF16 deploy:
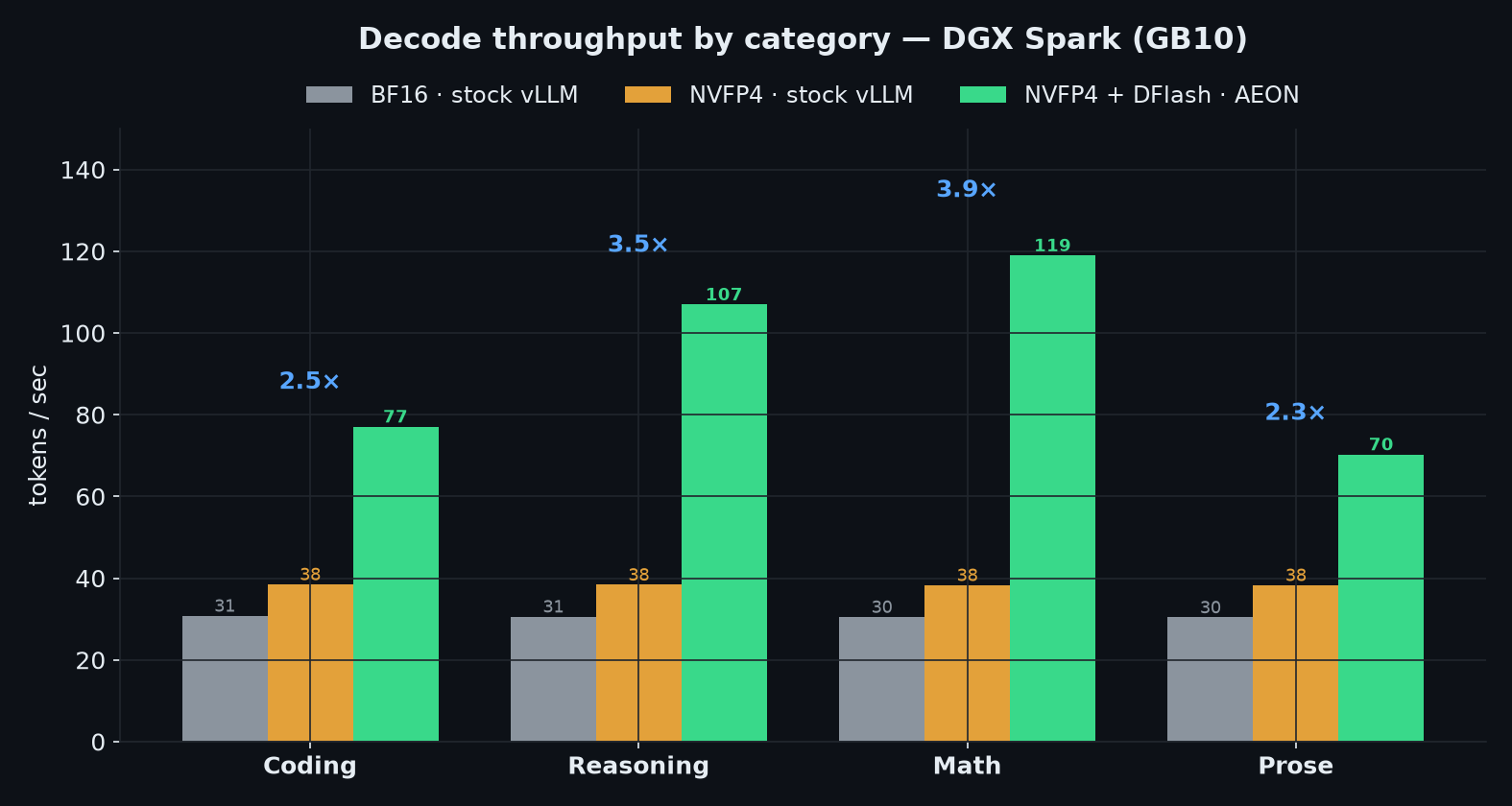
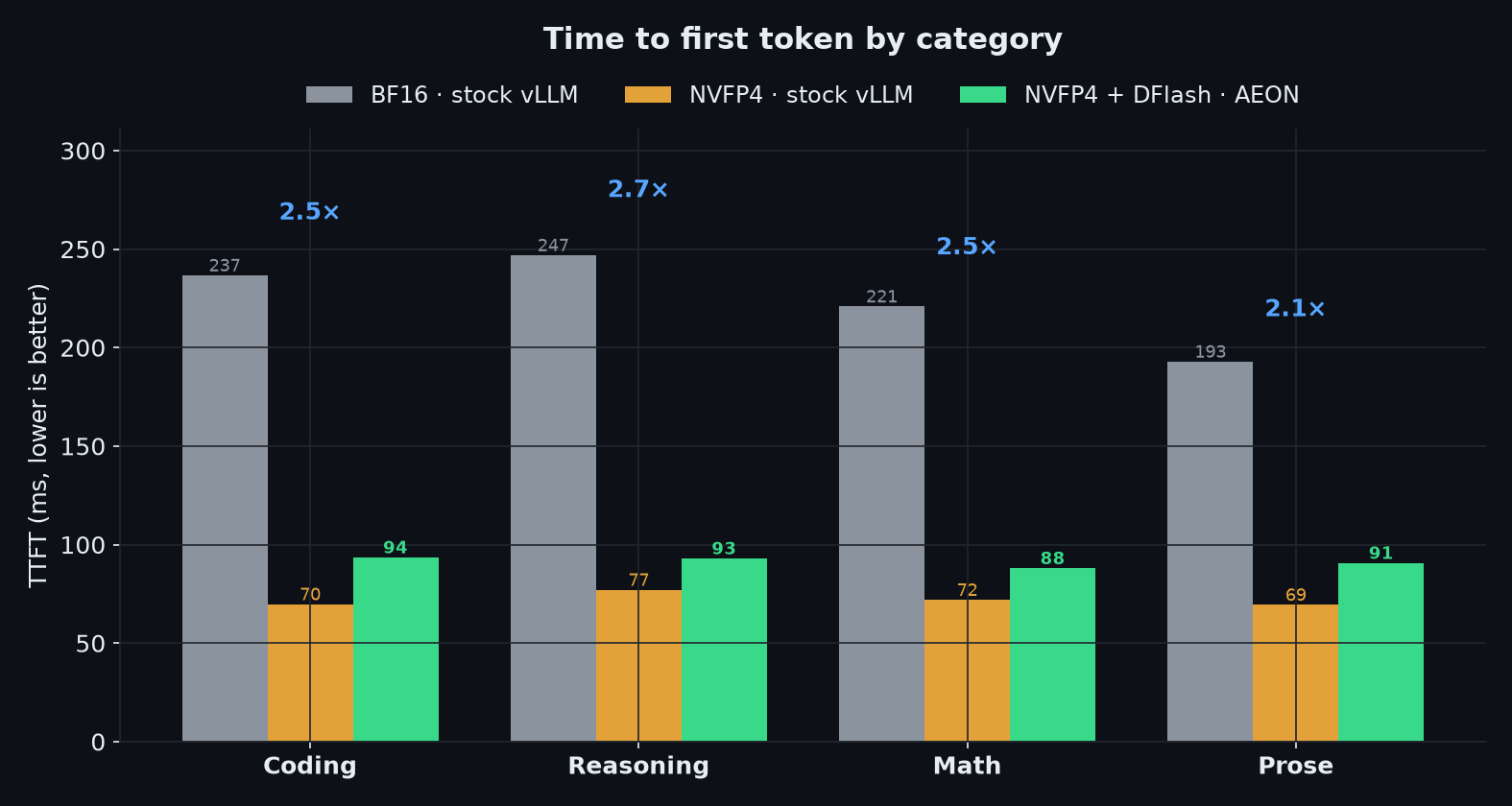
| Workload | BF16 · stock vLLM | NVFP4 · stock vLLM | NVFP4 + DFlash · AEON |
|---|---|---|---|
| Coding | 30.8 tok/s · 237 ms | 38.5 · 70 ms | 77.1 · 94 ms |
| Reasoning | 30.6 · 247 ms | 38.4 · 77 ms | 107.0 · 93 ms |
| Math | 30.5 · 221 ms | 38.3 · 72 ms | 119.0 · 88 ms |
| Prose | 30.4 · 193 ms | 38.3 · 69 ms | 70.3 · 91 ms |
| Avg decode | 30.6 | 38.4 | 93.3 |
| Prefill | 3,517 tok/s | 5,203 | 9,661 |
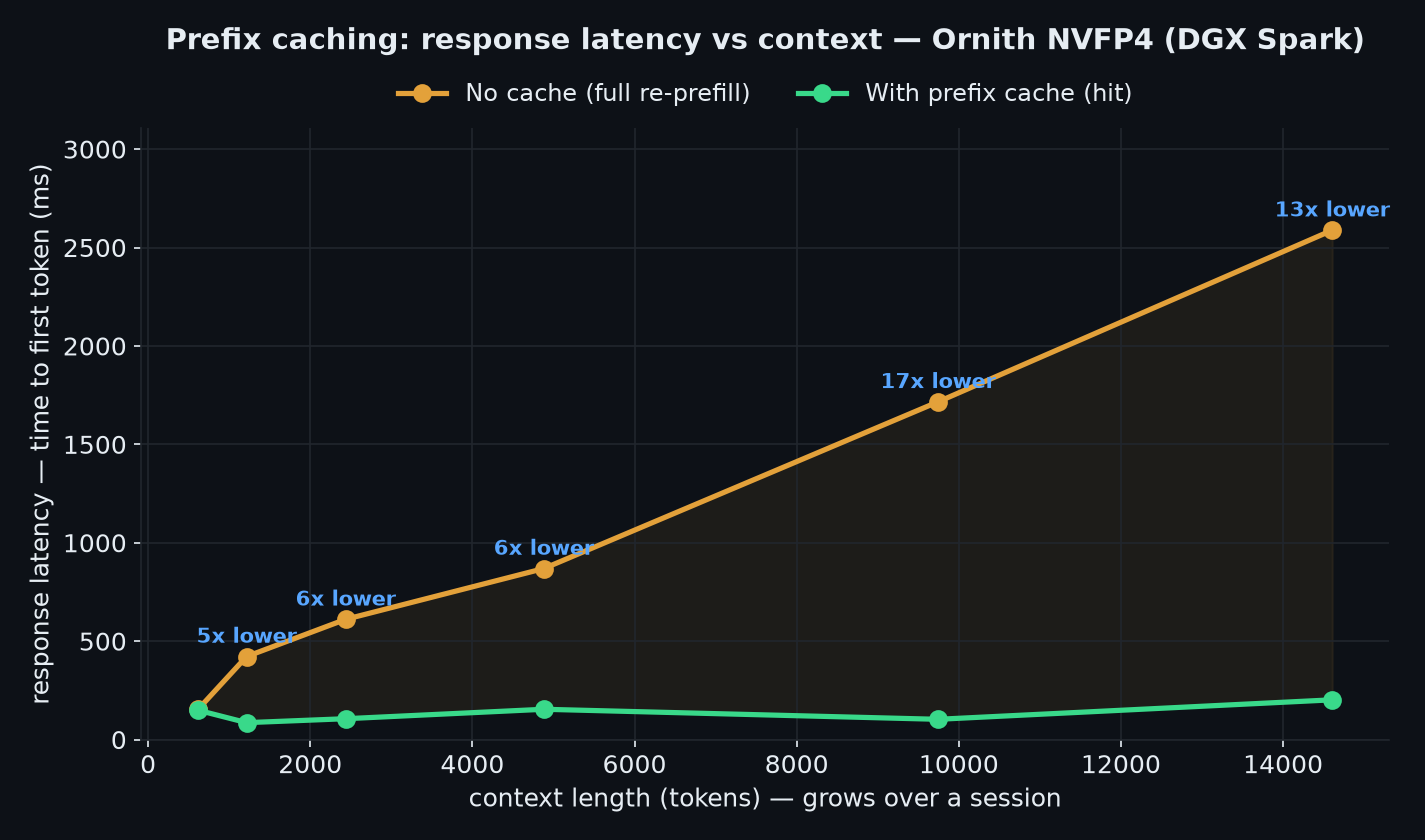
Prefix Caching
Repeated context benefits from prefix caching; cache-hit prefill remains ~100–200 ms while cold prefill grows with context length. Validated coherent and composable with DFlash.
| Context | No cache (re-prefill) | Cache hit | Speedup |
|---|---|---|---|
| 1.2k | 422 ms | 86 ms | 4.9× |
| 4.9k | 869 ms | 154 ms | 5.6× |
| 9.7k | 1,716 ms | 103 ms | 16.6× |
| 14.6k | 2,588 ms | 202 ms | 12.8× |
This is an uncensored model: safety refusals have been removed, placing full responsibility for appropriate use on the user. It requires a Blackwell GPU (B200 or GB10) and is hosted as a managed API via gigarouter.
best for
- ·Agentic coding with tool calling and code generation
- ·Multi-step reasoning and math problem solving
- ·Long-context dialogue and multi-turn chat
FAQ
A Blackwell GPU (B200, B100, or GB10) is required because the NVFP4 quantization relies on Blackwell's hardware support.
Yes, safety refusals have been completely removed through abliteration, and the 4-bit quantization preserved that behavior. It will generate any content instructed, without internal refusal.
On a DGX Spark, BF16 yields ~30.6 tok/s decode; NVFP4 stock gives ~38.4 tok/s (1.25x) and ~72 ms TTFT (3.2x faster than BF16's ~230 ms).
Yes, DFlash speculative decoding with a Qwen3.6-35B-A3B drafter achieves up to 1.89x single-stream decode (73.8 tok/s) at n=6 speculative tokens, but requires BF16 KV and a capped max-num-seqs of ~16 for stability.
Use the gigarouter OpenAI-compatible endpoint with your own API key, specifying the model name as "AEON-7/Ornith-1.0-35B-AEON-Ultimate-Uncensored-NVFP4" or a configured alias.
We're benchmarking and onboarding Ornith 1.0 35B AEON Ultimate Uncensored as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.